GRAPH-BASED PARSER: NODE PREDICTION
by Jane Imrie
Overview
Semantic Graph Parsing involves parsing the semantic meaning of a sentence and representing it in graph form. The process is comprised of concept identification, otherwise known as node prediction, and relation identification. We investigated the use of pre-trained transformers, namely SpanBERT, on concept identification. We also compared these models to the combination of BiLSTM and regular Glove embeddings. Furthermore, we explored whether an additional and costly Conditional Random Fields “layer” is worth including in a model i.e. how the layer affects the metrics of tag accuracy, node prediction precision, recall and the F1 score. Our research shows that SpanBERT was able to substantially outperform Glove across all categories. We also show that a CRF layer does not have a significant effect on model accuracy.
Introduction
Natural language Processing uses many different types of computational techniques in order to perform linguistic analysis on a variety of texts across languages, with the broad goal of trying to achieve human-like language processing over a variety of applications. One way this can be achieved is through syntactic and semantic parsing of sentences into various representations. These representations can then be used to perform a number of downstream NLP tasks, such as machine translation, question-answering and sentiment classification. We leverage deep learning technologies and techniques for tasks within the field of NLP. Semantic meaning representation parsing is the process of converting some form of input sentence into a semantic meaning representation.
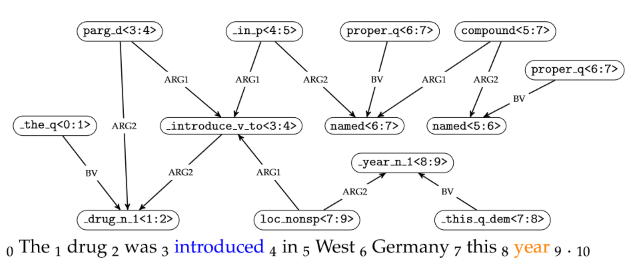
A number of frameworks exist which provide rules for the parsing process, such as Dependency-based Minimal Recursion Semantics, Elementary Dependency Structures (the choice for this project), Prague Semantic Dependencies, Universal Conceptual Cognitive Annotation and Abstract Meaning Representations. See image for example on an EDS graph.
For this project we investigated and compared the use of the BiLSTMs and pre-trained transformer model on node prediction accuracy, which is measured in terms of precision, recall and the F1 score. Furthermore, we determine the effect the addition of a probabilistic Conditional Random Fields layer has on model accuracy and assess if it would thus be worth including given its quadratic cost.
Background
Natural Language Processing and Computational Linguistics
"Sequence labelling" can be thought of in the general sense as a pattern recognition task. Given a sequence of values, an algorithm is used to assign a categorical label to each value. It includes POS tagging and NER.
We use the part of speech (POS) system to categorise words in a sentence. For example, English would generally label “smoking” as a verb, but this classification changes depending on the context and other words in the sentence. E.g – “It’s a cold breeze” vs “She breezed through the exam”. Part of speech tagging is the process of assigning labels to words, based on their contextual information
Proper nouns, like “Cape Town” are semantically viewed as different types of entities, referred to as named entities. These are not strictly proper nouns and include other attributes like currency, dates, etc. Named entity recognition (NER) can be defined as the process of identifying and tagging spans of text that can be classified as named entities. BIO tagging is one of the NER tagging methods and it performs NER by treating it as a word-by-word sequence labelling task, using tags that capture the boundaries of the span, as well as its type. A token that begins with the span is labelled with a “B”. Any tokens that occur inside the span are labelled with an “I”, and any tokens outside the span are labelled with “O”. There are a number of algorithms which exist to perform sequence labelling, but we chose conditional random fields for this project as CRFs are comparatively far more flexible (than other algorithms) in how it can use a word’s context. This is favourable, as often a word’s context can play an important role in what its correct label is. That is, knowing a lot about the preceding or following words for the one under consideration is a feature that would be needed to achieve high accuracy for tagging tasks.
Research Questions and Problem Definition
RQ1. How does a fine-tuned BERT encoder compare to an BiLSTM with a standard word-embedding layer in terms of accuracy of node prediction?
RQ2. To what extent does the addition of a CRF layer affect model accuracy, measured in terms of precision, recall and F1 score?
Problem Definition
We cast concept identification as a sequence labelling problem of two parts, given that we are separately predicting surface/lexicalised and abstract/non-lexicalised concepts. The first is the lexicalised concept prediction. In the context of this research we are trying to predict nodes, which are composed of spans. Surface span prediction can thus be seen as being most similar to an NER problem. Second, given that we transformed the abstract node labels into a set of tags who structure itself encodes the span information, the prediction of these tags is somewhat analogous to a POS tagging problem.
Evaluation

For our experiments, the micro-averaged precision, recall and F1 score was used to calculate the node label accuracy. The gold (i.e. target) spans are extracted from the data. In this context, a labelled item consists of a node label and span information. For both gold and predicted spans, any unlabelled token is removed from the set before the aforementioned metrics are calculated.
Experiments
A pipeline was implemented in order to facilitate the running and rerunning of experiments. Node prediction accuracy was tested using the development data set and a final evaluation was performed with the test set.
The baseline for this experiment are the models with the standard Glove embeddings. Each node label is fed one at a time into this embedding layer before being passed to the BiLSTM layer. From there, it is passed through a softmax function and a predicted label is returned. SpanBERT was the transformer selected for the models. Hyper-parameter tuning was performed in order to find the optimal learning rate and dropout for each model.
Results
| Concept | ||||
|---|---|---|---|---|
| Embedding | CRF? | Precision | Recall | F1 |
| Glove | No | 0.78 | 0.77 | 77.65 |
| Glove | Yes | 0.78 | 0.76 | 77.04 |
| BERT | No | 0.91 | 0.91 | 91.13 |
| BERT | Yes | 0.92 | 0.91 | 91.34 |
The results table shown here, provides an overview of the performance of each of the models. We can see that the BERT surface models scored the highest across all categories, substantially outperforming the best Glove surface model by over 10% for the F1 score. Additionally, we note that the Glove surface model without the CRF layer performed marginally better than the model that did have it. The converse is true for the surface transformer models - BERT with a CRF only scored slightly higher across all categories.
Conclusions
These experiments have demonstrated that BERT, a contextualised word representation model and transformers, surpasses the more “standard” Glove embeddings. CRF layers add additional model complexity and require more computational resources but are not worthwhile, given the minimal effect they had on node prediction accuracy.
 ©
2022 (2019) Design by Participating Students (Template: All Rights Reserved. Design by
©
2022 (2019) Design by Participating Students (Template: All Rights Reserved. Design by
