GRAPH-BASED PARSER: EDGE PREDICTION
by Claudia Greenberg
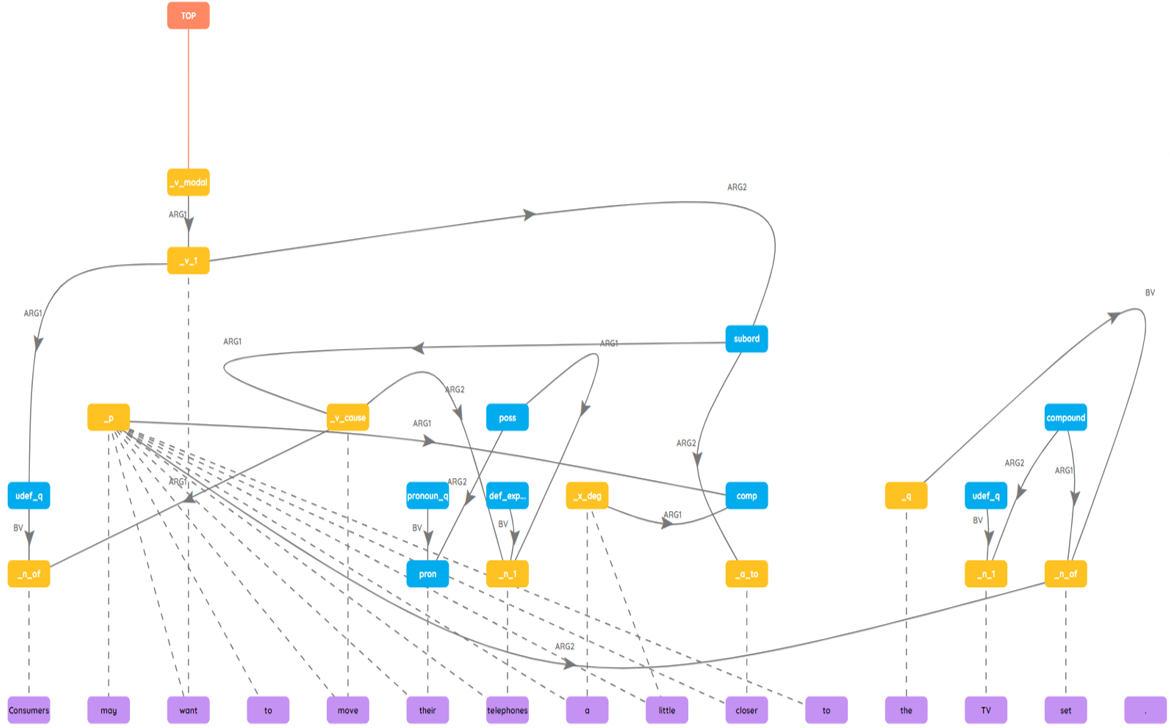
Overview
Semantic Graph Parsing is a highly-researched and highly-demanded
field of Natural Language Processing. There have been recent developments
within the area that changes how accurate and efficient a
parser can become, particularly the introduction of Transformer
Neural Networks. This research Honours Project Paper presents
additional research into the effectiveness of these Transformers in
the development of the Edge Prediction Component of a Semantic
Graph Parser. Additionally, it delves briefly into the effectiveness
of using Maximum Entropy Loss as a means of training a model.
The results presented in this paper provide limited results by attempting
to compare pretrained BERT Transformers, as opposed to
non-trained LSTMs. Furthermore, limited results in this paper are
presented comparing Maximum Entropy Loss to Maximum Margin
Loss. However, no official conclusion may be presented. Given the
paper's limitations and scope, this work provides a solid foundation
for additional research and it covers only a finite number of
subtopics, yielding potential for future work in its areas of research.
Introduction
The Computer Science field of Natural Language Processing is one
that is vastly studied in more recent years, due to its wide range
of uses and due to the introduction of Deep Learning and increasing
computational power. The overall aim of this field is for computers
or machines, of any kind, to be able to decode and understand
the syntactical structure and semantic meaning of natural human
sentences, no matter the complexity. This can be achieved by
receiving formal representations of such sentences.
Under the field of Natural Language Processing is a task called
Meaning Representation Parsing. This task aims to convert, or
encode, natural human sentences into specific formal representations
(depending on the context and machine) that the machine can
understand. One way that this can be done is in a graphical
representation, such as a task called Semantic Graph Parsing. This
is the focus of this paper.
A Semantic Graph Parser (SGP) creates said graphs. The parser
needs to be as accurate and efficient as possible for every possible
sentence within the language(s) it is trained for. Using this
understanding, these models would be able to both predict other
sentences and fill in omitted words in a sentence. This can be done
using various techniques and components.
Recently, a newer type of Neural Network has been developed,
called the Transformer, which addresses some of the issues pertaining
to the other preexisting types. Transformers are becoming a popular
option within parser design and have yet to be fully explored
within this specific field of work.
Our paper proposes another attempt at accurately predicting
the edges between the nodes, given the correct nodes. It aims to
investigate some of the techniques that have been used to create
accurate, efficient edge prediction modules. Our paper uses the Elementary
Dependency Structures (EDS) framework and is solely focused on
the English language.
Project Objectives
The main aim of the edge prediction module is to understand and
predict the edges of a semantic graph with the highest possible
accuracy. This forms the second pipelined stage of the graph-based
Semantic Parser. The following questions are thus proposed:
RQ1. How does the accuracy of an edge prediction module, developed using pretrained BERT, compare to parsers’ edge
prediction modules developed with non-trained LSTMs?
RQ2. How does the accuracy of an edge prediction module with a
Maximum Entropy training objective (loss) compare to edge
prediction modules that utilise a Maximum Margin training
objective (loss)?
Architectural Structure & Experimental Setup
Given an English sentence and its corresponding nodes, we want
to be able to predict the edges that connect the nodes together, in
order to form a complete representation of the sentence.
The edge prediction module can do this, first, by assigning a score
to every single possible edge (in other words, an edge from every
node to every other node), whereby the higher the score, the more
likely that the edge is correct. Subsequently, the module must then
choose a combination of such edges to yield the highest-scoring
graph. This will complete the entire formalism for the sentence at
hand.
The development process consisted of a heavy code aspect and
all coding was developed using Python. The main package used
was PyTorch. Implementing a high-quality Biaffine Network is not a straightforward
task with built-in functions. Therefore, implementing
this from scratch is out of scope for this paper. A Python codebase was chosen as a foundation
called SuPar, which was created by Yu Zhang. It is publicly accessible on GitHub.
This implementation is based, specifically, off of the project's Biaffine
Semantic Dependency Parser.
There are three main sections used to construct the module:
- Data Encoding and Preprocessing: The data is preprocessed, placed into an appropriate format and adapted for the inclusion of spans.
-
Biaffine Network for Individual Edge Scoring: This is a complex, effective edge-scoring structure often used for this task.
The components of the network are depicted in the figure below.
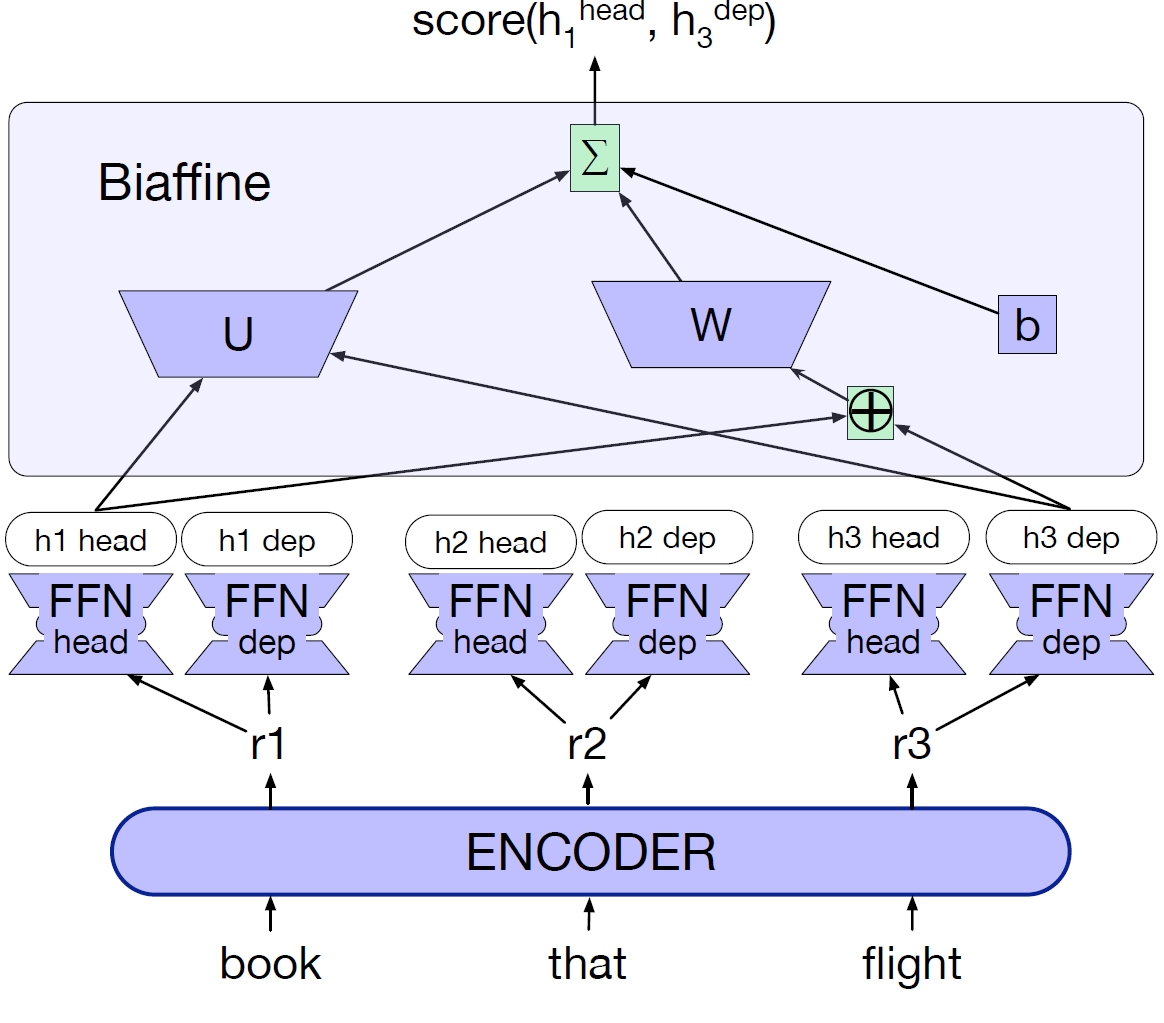
- Overall Graph Scoring Algorithms: This is the algorithmic component that takes all of the edges' scores, as input, and computes the highest-scoring combination of edges to create the final Semantic Graph. Both the greedy algorithm and the Chu-Liu Edmonds Algorithm are explored.
Loss Function
The Cross Entropy Function was used as the criterion to be optimised in the module. We attempted to compare this to the Maximum Margin training objective.
Evaluation
In order to answer the research objectives posed, an evaluation
process needs to take place. This evaluation calculates how accurate
the parser module is by comparing the predicted edges of an
inputted sentence to the gold (expected) edges of that sentence.
We utilise three common, main metrics to evaluate this
module: Precision, Recall and F1 Score.
Results & Discussion
A working edge prediction module was developed successfully
during the paper's implementation. Initially, the module used pretrained
BERT and assumed that tokens corresponded to nodes in a
1:1 fashion. After this module trained and predicted successfully,
we adapted the code to separate the nodes and tokens in order to
allow for a non-1:1 correspondence. Subsequent to the success of
this stage was the BiLSTM adaptation of the span module, which is
used to answer both of the research questions.
Due to the time limitations, only the BERT and BiLSTM Biaffine
modules (both using Maximum Entropy Loss) were successfully
developed before the paper's deadline. However, despite the successful
training, the BiLSTM module failed to provide satisfactory
results. Therefore, no valid evaluation scores could be outputted.
The BERT module produced a high result, with an F1 score of 96.42%.
We aimed to answer both of our research questions using the BiLSTM module.
Due to the sub-optimal results presented in our developed BiLSTM
module, no official conclusions can be made.
The results presented are severely limited. However, this paper provides
a solid foundation for future work to be conducted and, with additional
module tuning, the results can be updated and validated.
Conclusions, Limitations & Future Work
In this paper, we produced additional research within the topic of Semantic Graph Parsing. We attempted to develop and compare two edge prediction modules, one using BERT embeddings and one using a BiLSTM with Character and GloVe embeddings. Additionally, we briefly delve into the effectiveness of the Maximum Entropy Loss Principle, as a means to measure a model's loss, as opposed to Maximum Margin Loss. Using the results above, we cannot provide confident conclusions to answer our research questions. However, we have provided evidence that the modules developed are viable and, given additional time, further hyperparameter tuning can improve the BiLSTM module. We believe that this paper provides a solid foundation for future work, which will aid the research and evolution of Semantic Graph Parsing techniques.
Limitations & Future Work
In our paper, we outline several limitations and future work opportunities. Limitations include:
- A lack of immediate understanding of the preexisting codebase's full structure, scope and intricacies.
- A limited time frame, resulting in incomplete development of all planned modules and features.
- A lack of extensive hyperparameter tuning of the suboptimal BiLSTM module.
Future work recommendations include, but are not limited to:
- More extensive hyperparameter tuning.
- Finishing the Maximum Margin adaptation.
- Investigating the effect of different graph-scoring algorithms.
 ©
2022 (2019) Design by Participating Students (Template: All Rights Reserved. Design by
©
2022 (2019) Design by Participating Students (Template: All Rights Reserved. Design by
