Overview
The widespread use of computers and networks has brought many advantages but has also introduced new security challenges, primarily in the form of malicious software, or malware. Malware encompasses various types of software designed to infiltrate systems without permission, often for financial gain. Detecting malicious network traffic is crucial for internet system safety, but traditional methods face difficulties with modern network procedures, like encryption. Deep learning offers an alternative approach for classifying network traffic.
While there are numerous sub-categories of malware, we focus attention on Botnets and Ransomware. We selected Botnets out of recognition that the increasing number of security-vulnerable Internet of Things (IoT) devices offer an ideal landscape for botnets. A botnet defines a distributed network of computers, or bots, infected with software that enables the bots to be controlled by a malicious operator, or botmaster. Ransomware is a form of malware that encrypts a user’s files/devices, denying them access to these files/devices until a sum of money (the ransom) is paid. In 2022, there were 493 million ransomware attempts, a 162.29% increase since 2019.
Existing approaches to prevent malware are not new, and they typically use Network Intrusion Detection Systems (NIDS). However, these methods have become less effective due to evolving networking practices. Port numbers and blacklisted IP addresses are no longer reliable indicators of malicious activity, and encryption protocols in network traffic make packet payload inspection challenging. Given these limitations, the objective is to assess the effectiveness of different deep learning algorithms in detecting and classifying malware traffic.
Problem
A botnet defines a distributed network of computers, or bots, infected with software that enables the bots to be controlled by a malicious operator, or botmaster. These botnets attempt to hide themselves by transmitting normal traffic amongst their botnet traffic. However, a defining charac- teristic of botnets is the presence of command and control channels, through which the malicious operator is able to transmit instructions or receive information. A common instruction would be a distributed denial-of-service (DDOS) attack, where the bots flood a target to disrupt its service. It is this characteristic of botnets - that the bot must at some point connect to its botmaster - that may be leveraged to build detection models. When a bot connects to the botmaster, a sequence of network flows, defined as a grouping of related traffic, can be extracted from the generated traffic, from which a deep learning (DL) model will be able to learn distinguishing patterns.
Research Objectives
Botnet Detection
We implement five binary classification models, an MLP, shallow CNN (v1), deep CNN (v2), AE, and AE+CNN, which serve as models for botnet detection. With respect to each classifier, we aim to:
- Evaluate the accuracy, FPR, and FNR on the standard and proto zero-day test set.
- Evaluate how reducing the feature space, into 50% and 30% samples, impacts the memory requirements, inference time, accuracy, FPR, and FNR of the models.
Botnet Classification
We implement five multiclass classification models, an MLP, shallow CNN (v1), deep CNN (v2), AE, and AE+CNN, which classify traffic into botnet families. With respect to each classifier, we aim to:
- Determine the overall accuracy, and accuracy respective to each class, when evaluated on the standard test set.
- Evaluate how reducing the feature space, into 50% and 30% samples, effects the memory requirements and inference time, in relation to the overall accuracy of a model.
Dataset and Preprocessing
The Stratosphere Research Laboratory provides a repository featuring both malicious and benign traffic captures. We utilized the CTU-13 dataset, encompassing traffic from seven unique botnet families alongside normal traffic, all captured in PCAP format. Flow extraction from these PCAP files was achieved using the open-source tool, CICFlowMeter, resulting in bi-directional flows characterized by 84 features. These features delineate statistical packet flow details for specific sessions. However, certain features like IP addresses and port numbers were omitted due to their susceptibility to manipulation techniques like dynamic IP addressing, port-obfuscation, and IP spoofing, which impede reliable classification. Furthermore, to enhance model generalization on unseen data, intrinsic identity-related features were excluded from the training set.
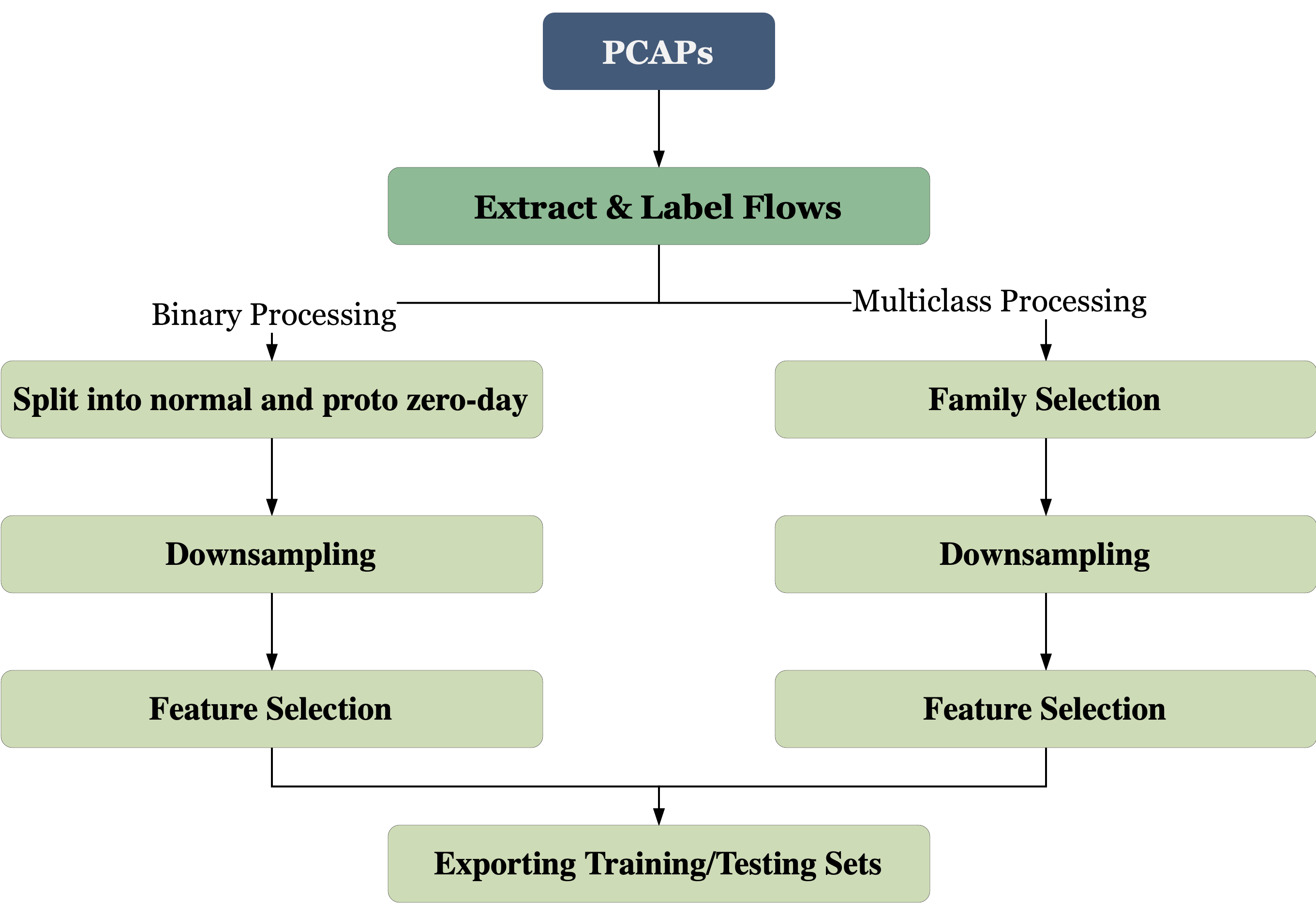
In constructing binary and multiclass datasets, network flows were systematically labelled. The binary set
comprised 60,000 malicious instances from select botnets (Neris, Rbot, Virut, Menti, Sogou) matched with 60,000
benign counterparts. An auxiliary zero-day dataset was curated from the Murlo and NSIS.ay botnet families to
evaluate model robustness against novel threats.
For multiclass endeavors, a threshold of 30,000 samples per class was empirically set for classifier efficacy.
This criterion necessitated the omission of several botnet families, notably Sogou, Menti, NSIS.ay, and Murlo.
The
refined dataset encompassed benign, Rbot, Virut, and Neris classifications, each balanced at 45,000 samples.
Subsequently, divisions were made at a 72%, 8%, and 20% ratio for training, validation, and testing
respectively.
Experiments
Binary Classification Experiments
1. Comparing the Classification Performance of Models Evaluated on Normal and Proto Zero-Day Test Set
This experiment establishes a baseline evaluation of how MLP, CNN v1, CNN v2, AE, and AE+CNN perform, in terms of classification ac- curacy, FPR, and FNR on the conventional testing set. Subsequently, these models are evaluated on the additional proto zero-day testing set, to ascertain their ability to generalise to unseen botnet families.
2. Evaluating the Effect of a Reduced Input Feature Space on Computational and Classification Performance
Computational performance is defined by memory usage (MMU) and inference time (MIT). Accurate metrics are hard to obtain due to concurrent processes and OS memory management. We observed memory consumption increasing with each model iteration, risking bias towards early-evaluated models. To mitigate this, we measured MIT and MMU across batches of 100 test samples, rebooting the system after each batch. Memory was profiled using Python's 'Memory Profiler' package, and inference time was measured using the 'timeit' package. Metrics were averaged over three runs for each model, using feature sets of 100%, 50%, and 30%.
Multiclass Classification Experiments
1. Evaluate the Classification Accuracy of each model over- all, and for each Botnet Family
The experiment tests MLP, CNN v1, CNN v2, AE, and AE+CNN models for overall and per-class accuracy in botnet family identification. FPRs and FNRs aren't suitable for multiclass problems. We use the standard test set only, dismissing proto zero-day sets as incompatible with multiclass classification. Each class is balanced with 8000 samples, justifying the use of accuracy as a metric. Models are evaluated using Keras' 'predict()' method, and results are stored in a confusion matrix.
2. Evaluating the Effect of a Reduced Input Feature Space on Computational and Classification Performance
We evaluate the effect of reducing feature spaces on both computational and classification performance by training five different models on three datasets. These datasets contain 74, 37, and 22 features, which correspond to 100%, 50%, and 30% of the total features, respectively. For computational performance, we focus on measuring the model's mean inference time (MIT) and mean memory usage (MMU). Classification performance is primarily gauged by a model's overall accuracy across all classes. We also pay attention to the rate of misclassified traffic to identify whether specific models have difficulty classifying certain botnet families, or if some families are consistently poorly classified across all models.
Results
Binary Classification Results
In the evaluation of machine learning models for botnet detection, the Convolutional Neural Network version 2 (CNN v2) outperforms both the Multi-layer Perceptron (MLP) and the Autoencoder (AE). Specifically, CNN v2 shows the highest accuracy on a standard testing set, followed by the MLP and then the AE. While these high accuracies suggest that botnet detection is not exceedingly complex, the performance variations between the models are noteworthy.
The lower performance of the AE models could be attributed to the encoding phase's inability to capture critical features of the input data. This limitation is particularly significant when considering high-traffic network environments, where even marginal error rate improvements could result in thousands of fewer false positives and negatives.
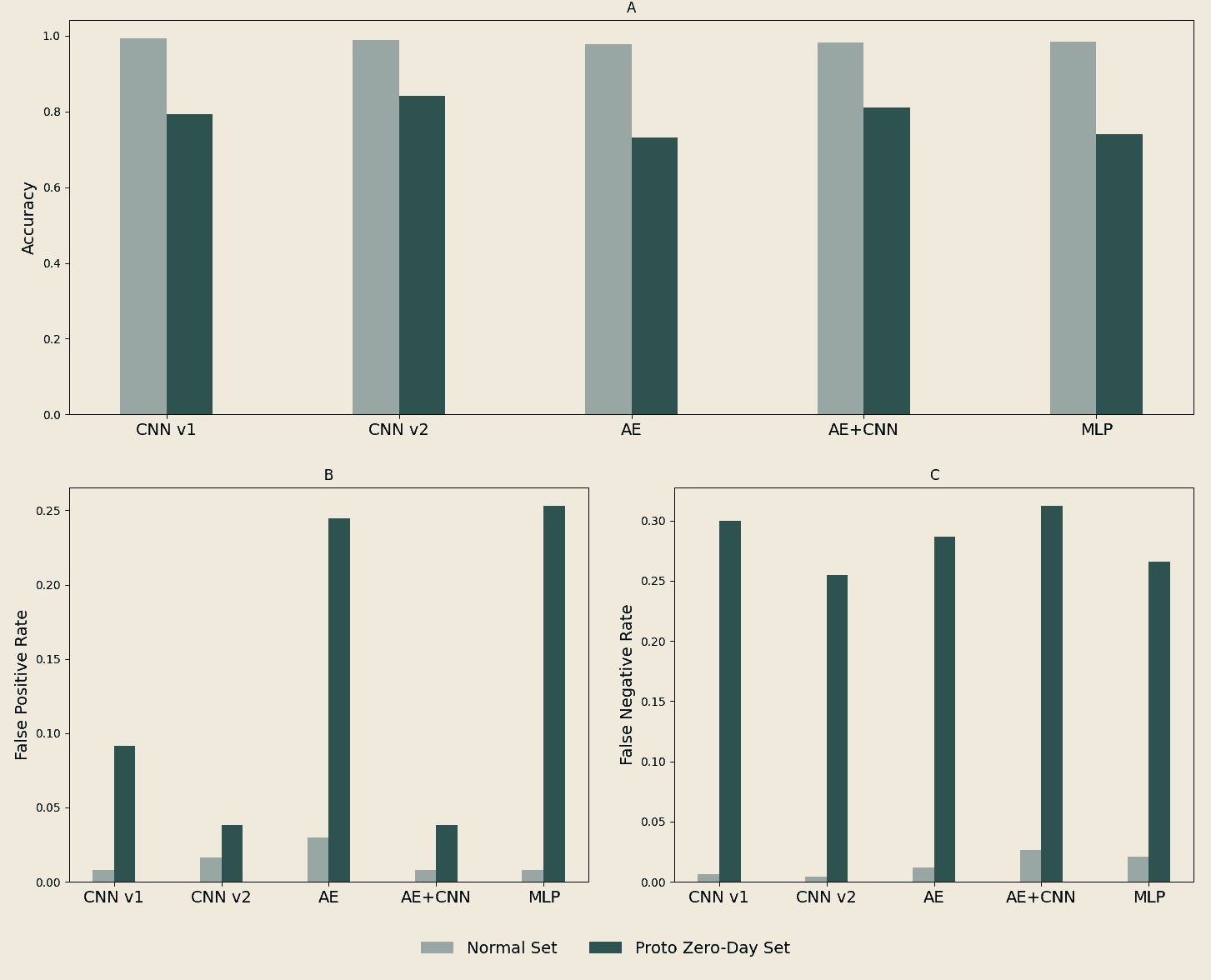
When evaluating the models' False Positive Rate (FPR) and False Negative Rate (FNR), similar trends emerge, with CNN v2 demonstrating better performance overall. Interestingly, CNN v2 shows a decline in its FPR compared to an earlier version, which could indicate a risk of overfitting due to its increased complexity.
Performance declines across all models when tested on a proto zero-day dataset, which includes botnet families excluded from training. This suggests that while the models are capable of high accuracy when dealing with known entities, their generalization to unknown families is poor. The variability in performance on the proto zero-day dataset further suggests that models like CNN v2, which incorporate convolutional layers, are better suited for capturing complex, generalized botnet behaviors. In contrast, AE and MLP models, which excel at learning specific features of known botnet families, struggle to generalize this knowledge to new, unknown families.
Multiclass Classification Results
| Model | Accuracy | Memory (MB) | Inference Time (S) | ||||||
|---|---|---|---|---|---|---|---|---|---|
| % features | 100 | 50 | 30 | 100 | 50 | 30 | 100 | 50 | 30 |
| CNN v1 | 0.907 | 0.881 | 0.819 | 465.96 | 434.63 | 425.77 | 0.00030 | 0.00031 | 0.00027 |
| CNN v2 | 0.898 | 0.889 | 0.809 | 465.85 | 446.88 | 431.28 | 0.00029 | 0.00026 | 0.00025 |
| AE | 0.836 | 0.786 | 0.745 | 447.98 | 427.21 | 419.70 | 0.00024 | 0.00022 | 0.00022 |
| AE CNN | 0.836 | 0.807 | 0.755 | 492.95 | 478.88 | 458.87 | 0.00028 | 0.00030 | 0.00030 |
| MLP | 0.773 | 0.764 | 0.684 | 445.69 | 425.44 | 418.13 | 0.00023 | 0.00023 | 0.00022 |
We have just proposed that a CNNs’ ability to capture hierarchical relationships in data may be an explanation for their effectiveness for this problem; consequently, we suggest that an explanation for the relatively poor performance of the AE+CNN, which should benefit from this property of the convolutional layers, is that the encoding phase of the network reduces the complexity of the data to a point where the subsequent CNN is unable to learn the necessary hierarchical relationships, because they no longer ‘exist’ in the encoded representation.
The three models that employ a CNN appeared to use more memory than the AE and MLP. We expect the MLP to use the least memory, as it is the least complex model. However, the CNN v1 has fewer trainable parameters than the AE, while using more memory. We suggest that the cause of this, and a general explanation for why CNNs seem to have the largest MMU, is that the CNN has to store filters and their respective activation maps in memory, which can become fairly expensive.
We find that in every model, there is an increase to MMU as the feature space increases. This was an expected result: that larger input feature spaces are associated with an increase to a model’s MMU. However, we maintain that this increase to MMU represents a relatively small improvement to computational performance, and is often coupled with a fairly substantial improvement in classification performance.
Conclusion
For our first research objective, we found that all models achieved accuracies ≥0.979, FPRs ≤0.033, and FNRs ≤0.026, suggesting that the classification problem was fairly simple. Classification performance declined on the proto zero-day set overall, and clearly showed that CNNs were more capable algorithms at detecting zero-day traffic.
We further observed a clear trend that larger feature spaces where associated with a larger MMU, affirming our expectation that feature selection might improve computational performance. However, in reducing feature space we also observe a substantial decline in classification performance. We found no evidence of a trend between feature space size and MIT; however, we acknowledge that there were serious limitations to the accuracy of measuring MIT.
With respect to the second research objective, we found a fairly large differential between the classification performance of models which used convolutional layers and those that did not. We suggest that the efficacy of CNNs at learning hierarchical relations between features is an explanation for this. As with the binary classifiers, we observed a trend where larger feature spaces were associated with slightly greater MMU. However, the larger feature spaces resulted in substantially better classification performance.
Abstract
A recent increase in ransomware attacks has necessitated tools that can detect threats within a computer network. Machine learning (ML) has been proposed as a solution to detect ransomware within network traffic. However, whilst many ML models are developed to obtain high classification accuracy, we also test their runtime memory performance and inference times. We further test the effect training the models on a reduced feature space has on the classification and computational metrics. In this study, we evaluate multi-layer perceptrons (MLP), 1-dimensional and 2-dimensional convolutional neural networks (CNN) and long short-term memory (LSTM). Experiments are performed to give insight into each model's ability to reduce its false positives (FPs). We find a consistent increase in memory usage as the feature space increases and that the lowest amount of FPs is obtained when using 50% to 66% of the features. The study evaluates 17 models for their effectiveness in classifying ransomware network traffic. Efficiency in this context is considered a trade-off between accuracy, false positives, runtime memory usage, and inference time.
Research Objectives
- Assess the performance of MLP, 1D CNN, 2D CNN, and LSTM models in classifying encrypted network traffic as benign or ransomware, considering the accuracy, false positive/negative rate, inference time, and runtime memory usage of the models.
- Investigate the impact of using a window of samples on the accuracy, false positive rate, inference time, and runtime memory consumption on an LSTM by grouping multiple samples into one sample.
- Investigate the impact of dimensionality reduction on accuracy, false positive rate, inference time, and runtime memory consumption across the deep learning architectures (MLP, 1D CNN, 2D CNN, and LSTM) by decreasing the feature space from 30 samples down to 20, 15, and 5 samples.
Dataset
For this project, the Open Access Dataset (OA) was used. The OA dataset includes over 120 hours of ransomware traffic, comprising 94 samples from 43 different ransomware families, some of which have multiple samples. The dataset spans from 2015 to 2021, with varying packet counts and traffic durations among samples.The benign dataset in OA consists of normal network traffic generated by approximately 300 users on a campus network over one week, excluding weekends. Each day's traffic is segregated into its own subset.
For modeling purposes, the data is divided into four groups: the train set, validation set, test set, and extra test set. These subsets include both benign and ransomware network traffic, except for the extra test set, which exclusively contains benign traffic for false positive testing. The test set contains previously unseen network traffic but also includes ransomware from the same families present in the train set.
Experiments
The table below presents the experiments performed to address the research objectives of the project.
| Experiment | Description | Brief Deception Of Target Objective |
|---|---|---|
| 1 | Establishing a simple MLP baseline and training DL models |
Objective 1: Evaluate ML models for encrypted traffic classification |
| 2 | Varying window on input. | Objective 2: Sliding Window |
| 3 | Testing for false positives | Objective 1&2 |
| 4 | Varying input feature-length | Objective 3: Dimensionality reduction effect on models |
Results
The LSTM model outperforms others in accuracy, thanks to its ability to handle sequential network traffic, learn long-term dependencies, and deal with noisy data. However, the windowed LSTM (WLSTM) didn't perform as well due to reduced temporal resolution. The 2D CNN had the worst accuracy but the fewest false positives (FPs), indicating it may capture spatial patterns in benign traffic, while MLP had a higher accuracy but more FPs, likely due to dataset imbalance. LSTM handles class imbalance better.
| %Accuracy | False Positives | False Negatives | Inference Time (ms) | Memory Usage (MiB) | |
|---|---|---|---|---|---|
| MLP | 99.20 | 629 | 229 | 23 | 1961 |
| 1D CNN | 99.18 | 2 | 48 | 34 | 1972 |
| 2D CNN | 96.95 | 0 | 11353 | 37 | 1993 |
| LSTM | 99.85 | 530 | 19 | 89 | 1745 |
| WLSTM | 98.79 | 1054 | 75 | 26 | 6379 |
Regarding inference time and runtime memory usage, MLP is the fastest (0.0023 ms) and LSTM is the slowest
(0.0089 ms). This aligns with MLP's lightweight architecture. CNNs perform similarly, with LSTM using the least
runtime memory. WLSTM is less memory-efficient due to windowed processing, but this trade-off can lead to faster
inference times. All models have acceptable inference times below 25.74 milliseconds.

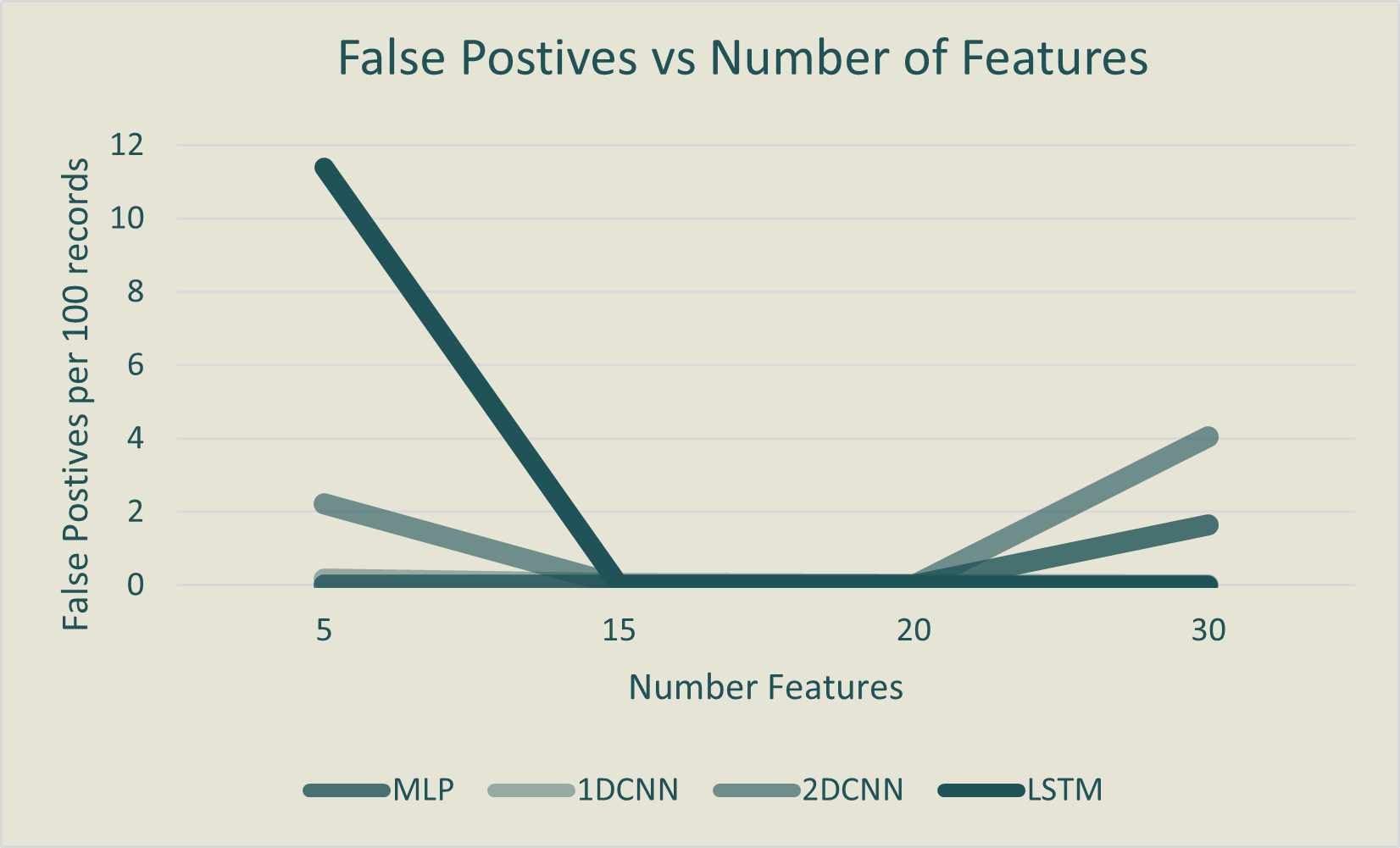
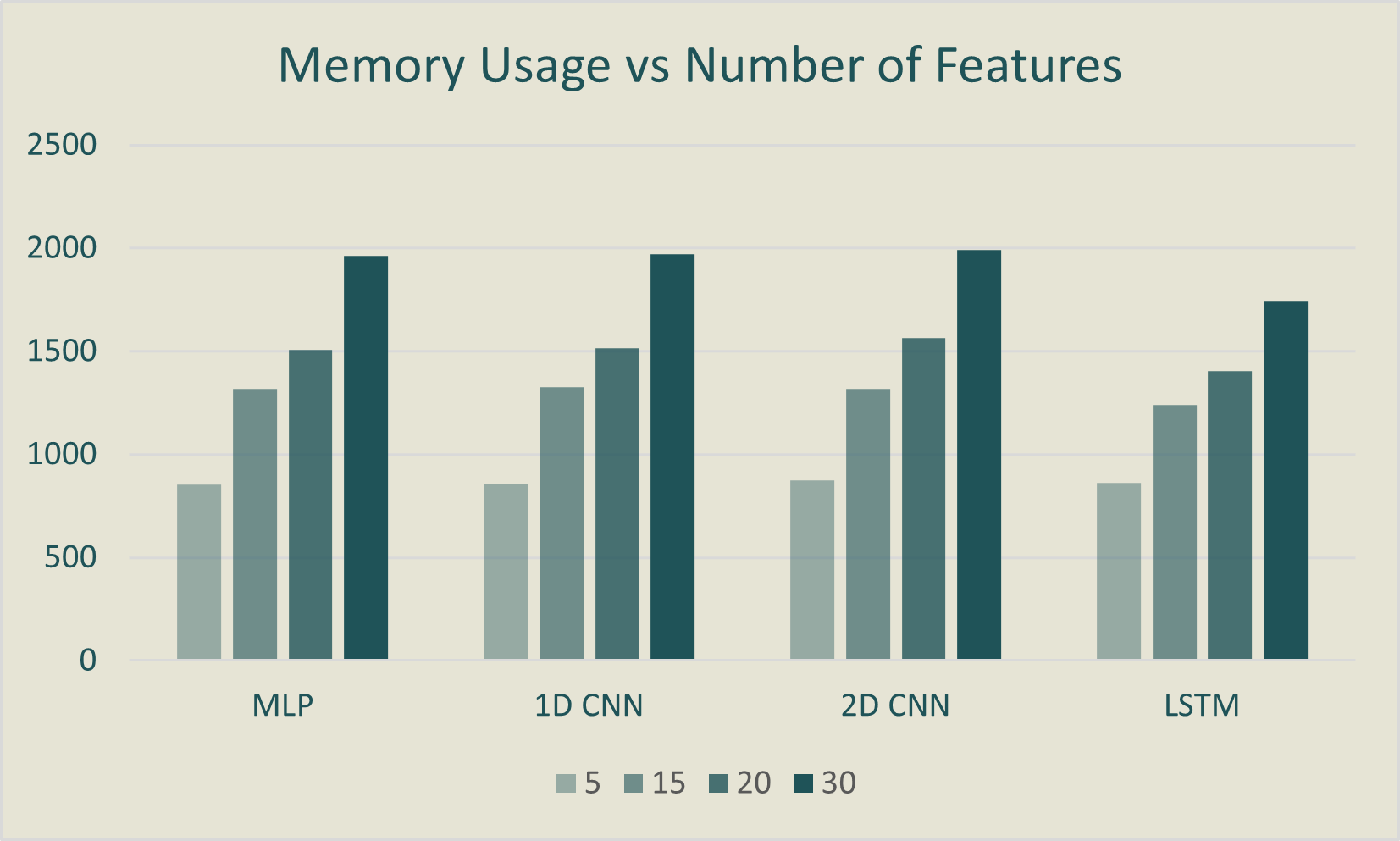
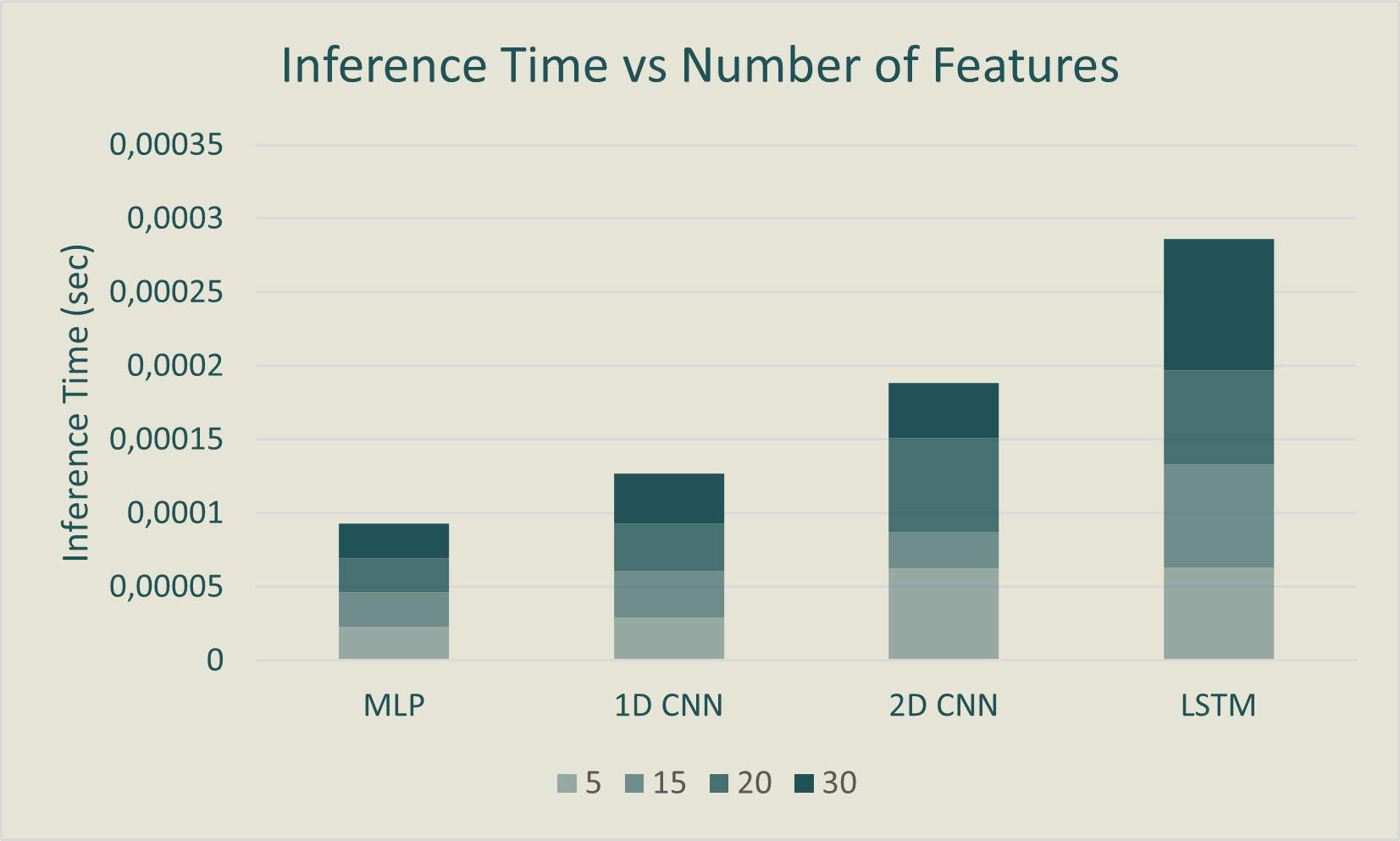
In the analysis of model performance with varying numbers of input features (5, 15, 20, 30), it's observed that
using all features results in high accuracies, but there's no consistent trend across all models when using
fewer
features. Surprisingly, the LSTM consistently maintains high accuracy with different feature counts, contrary to
previous expectations.
Concerning false positives (FPs), there's a "sweet spot" for all models, with the lowest FPs occurring when
using
15-20 features. This suggests that too few features may hinder learning, while using all features could
introduce
redundancy and confusion.
MLP stands out by performing well with just five features, indicating its effectiveness with fewer inputs.
However, models that yield low FPs but struggle to classify ransomware, like the 2D CNN, are less useful. In
contrast, the LSTM maintains high accuracy even with 20 features.
When considering runtime memory usage, as more features are used, it consistently increases across all models,
aligning with prior research. Inference time changes slightly with different feature counts, with the LSTM being
the slowest and the MLP the fastest. However, the number of features does not strongly influence inference time.
In summary, varying input feature sizes impact accuracy, FPs, and runtime memory usage. The LSTM performs well
across different input sizes, suggesting the sequential nature of network packet data. The optimal range for
minimizing FPs is using 50% to 66% of the feature set. Larger inputs lead to increased runtime memory usage.
Conclusion
In conclusion, this study evaluated the performance of various ML models for classifying encrypted network
traffic as ransomware.
We found that there is no universally perfect model, and the choice should align with specific network
requirements. Additionally, we observed that the number of features inputted into a model affects model
performance, with the 20-feature LSTM model consistently performing well. Dimensionality reduction did not
greatly impact inference time but increased runtime memory usage. Lastly, combining a sliding window of inputs
with an LSTM did not yield favourable results. Our findings emphasize the need for tailored model selection,
optimized input sizes, and carefully designed feature sets for effective ransomware detection in encrypted
network traffic.
For future work, network traffic could be collected from multiple networks to make the models more generalisable
to different network environments. Secondly, to further investigate dimensionality reduction, rather than
exclusively selecting the first x features, future studies could involve randomly selecting features to assess
the significance of feature quantity versus feature selection. Extending dimensionality reduction experiments to
different network traffic datasets can also test whether similar effects manifest across various datasets. To
reduce the inaccuracies when measuring runtime memory usage and inference time, future work could further
include measuring these metrics in a more isolated environment, where these metrics can easily be controlled.