Interactive Question Answering
Graph Attention Network
Roy Cohen
Overview
Within the context of text-based games, many agents fail to generalise and capture necessary meaning and relationships between objects found in the environment. A model failing to develop some contextual awareness of the world can be detrimental to performance. Current works indicate knowledge graphs (KGs) help express supplementary information about the world to facilitate decision-making whilst adhering to partial observability.
To this end, this study explores the use of Graph Attention Networks (GATs) in providing an RL agent with some contextual understanding about the environment with which it inhabits. Literature shows that GATs can aid aspects of performance such as steps required to complete a task and training convergence. Therefore, by embedding specific details about an environment into a knowledge graph and allowing an agent to use it to inform decision-making, this study explores the effects of Graph Attention Networks on agents’ accuracy on the QAit task.
Research Objectives
- Do Graph Attention Networks increase an RL agent's question-answering capabilities?
- Can Graph Attention Networks speed up the training convergence of an agent in an IQA system?
The QAit Task
Please read about the QAit task before continuing in order to understand the experiment settings, results and their metrics and overall context to the study.
Learn moreKnowledge Graph Contruction
 In order for an agent to learn a KG, a set of RDF triples, i.e. a tuple of (subject,
relation, object) are to be extracted and stored. The tuples are extracted from the
observations provided by the text-based environment at each agent step using Standford's Open
Information Extraction (OpenIE). However, OpenIE was not designed with the regularities of
Text-based adventure games in mind. To remedy this, Ammanabrolu et al (2019). outlined a set of
heuristic-based rules to fill in the information not inferred by OpenIE. Combining the
information extracted from OpenIE with the additional rules results in a KG that can provide an
agent with representation of the game world.
In order for an agent to learn a KG, a set of RDF triples, i.e. a tuple of (subject,
relation, object) are to be extracted and stored. The tuples are extracted from the
observations provided by the text-based environment at each agent step using Standford's Open
Information Extraction (OpenIE). However, OpenIE was not designed with the regularities of
Text-based adventure games in mind. To remedy this, Ammanabrolu et al (2019). outlined a set of
heuristic-based rules to fill in the information not inferred by OpenIE. Combining the
information extracted from OpenIE with the additional rules results in a KG that can provide an
agent with representation of the game world.
Every time the agent acts, the KG updates to reflect the new information provided by the game. However, to provide the agent with both long term and short term context, a special node "you" is introduced to reflect what entities are currently applicable to the agent. Using the "you" node, Ammanabrolu et al. developed the following set of rules used to update the graph after each agent action:
- Create a link between the current room node (e.g. "bedroom") to nodes representing the items found in the room, using the relation "has" (e.g. <bedroom, has, bed>).
- Linking information regarding entrances and exits to the current room node (e.g. <bedroom, has, exit to south>).
- All relations relating to the "you" node are removed, except for the nodes representing an agent's current inventory in the game (e.g. <you, have, key>).
- Link the different room nodes with directions based on the agent's action taken to move between the rooms (e.g. <bathroom, east of, bathroom>).
OpenIE extracts all the other RDF triples added to the KG.
Architecture
The diagram below shows the complete process, at each time step t, of the implemented system and its core components. The KG Constructor takes in the observation provided by TextWorld at time step t (denoted as Ot), the agent's previous action Ct-1 and the extracted relations and entities from OpenIE. Utilising the three inputs, it uses the set of heuristic rules defined in the above section to construct a KG. The constructor then uses a BERT model to obtain a set of node features at each time step ht. The GAT uses ht along with the edge indices (i.e. each node's neighbours) from the constructed graph to produce the set of output features h't. The Transformer Encoder turns the produced node features, h't, into a fixed-length summary St. This is then utilised by the agent's command generator when ranking actions to perform and by the question answerer when answering questions.

Results
The table below displayed agents' results for the QAit task on fixed and random mapped games. Question Answering accuracies are shown first, with the Sufficient Information scores in brackets. Highlighted results indicate better testing QA results compared to the other agent.
| Model | Location | Existence | Attribute | ||||
| Train | Test | Train | Test | Train | Test | ||
| 500 Fixed Map Games | |||||||
| GAT-DQN | 0.320 (0.320) | 0.176 (0.192) | 0.706 (0.183) | 0.702 (0.157) | 0.674 (0.024) | 0.530 (0.019) | |
| DQN | 0.430 (0.430) | 0.224 (0.244) | 0.742 (0.136) | 0.674 (0.279) | 0.700 (0.015) | 0.534 (0.014) | |
| 500 Random Map Games | |||||||
| GAT-DQN | 0.418 (0.418) | 0.226 (0.230) | 0.746 (0.151) | 0.702 (0.129) | 0.688 (0.026) | 0.476 (0.021) | |
| DQN | 0.430 (0.430) | 0.204 (0.216) | 0.752 (0.162) | 0.678 (0.214) | 0.678 (0.019) | 0.530 (0.017) | |
| Unlimited Random Games | |||||||
| GAT-DQN | 0.318 (0.318) | 0.212 (0.212) | 0.726 (0.152) | 0.708 (0.149) | 0.552 (0.026) | 0.512 (0.017) | |
| DQN | 0.316 (0.316) | 0.188 (0.188) | 0.728 (0.213) | 0.668 (0.218) | 0.812 (0.055) | 0.506 (0.018) | |
The inclusion of the GAT in the DQN model (GAT-DQN) in 500 fixed map games was not able to aid the DQN agent in achieving better Question Answering (QA) accuracy or Sufficient Information (SI) score for location and attribute type questions. The exception to this is the SI score for attribute types questions which performed higher than the DQN. GAT-DQN significantly outperformed the DQN in QA accuracy for existence type questions, increasing from 0.674 to 0.702.
In the 500 random mapped games, we see significant improvements for the location type questions for both QA accuracy and SI score while achieving lower measures in training for both. The GAT-DQN improved the QA accuracy from 0.204 to 0.226 and the SI score from 0.216 to 0.23, respectively. Once again, we can see lower QA accuracies for attribute questions and a higher SI score.
The results from the unlimited game experiments indicate an improvement in the GAT-DQN model's ability to answer all three question types compared to the DQN. The increase in training data variability allowed the GAT-DQN to increase the attribute QA accuracy from 0.506 to 0.512, unlike in the 500 game setting.
Discussions
The higher variability within the random map game's training and testing sets are more challenging to solve and require agents with higher generalisation abilities than with fixed mapped games. This relationship can be explored further by looking at the results from the unlimited games, which have maximum variability in training data and negligible possibility of overfitting to the training data. The results suggest that the higher variability in unlimited games allowed the GAT to improve the DQN's performance on all three question types, which was not the case on the 500 games setting.
We can also see that although training the GAT-DQN on unlimited games for location type questions improved QA and SI accuracy compared to the regular DQN, it is lower than the GAT-DQN model trained on 500 games. However, we see a more significant increase from the DQN baseline in unlimited games than 500 games, indicating that the higher variability in the training data still resulted in higher utility from the GAT. This implies that while the GAT's utility increases, it is limited by the agent utilising it as the DQN alone does worse on all three question types when trained on unlimited versus 500 games.
The DQN inherently performs poorly on unlimited games compared to 500 games. However, the GAT bridged the gap in its shortcoming to a marginal degree, as it still could not beat its accuracy from 500 games. This highlights that while evidence suggests that the GAT improves QA accuracy under more generalised environment conditions, the agents' QA accuracy is hindered by its own abilities. The long-term context provided by the GAT improves the QA accuracy but cannot alone solve the task.
Training Convergence
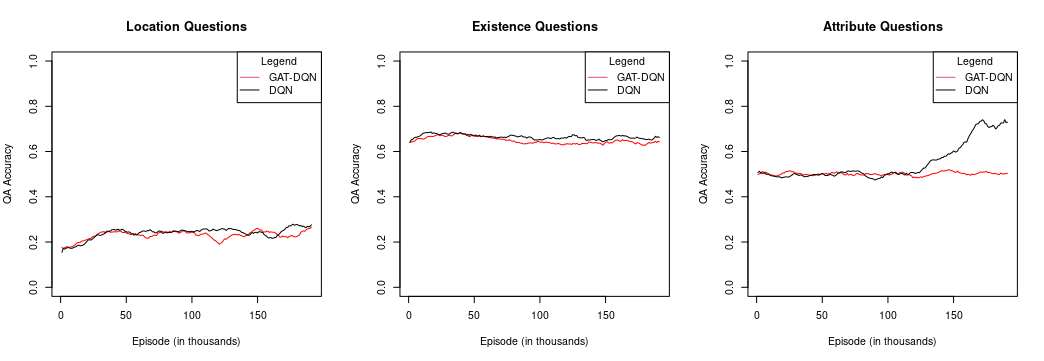
The plots show the QA accuracies for the baseline DQN agent and the GAT-DQN for unlimited games on random maps. The complete set of plotted training accuracies for all experiments run are in the paper. Analysing these curves shows that the GAT-DQN has slightly lower training QA accuracy in most of the experiments run. In the unlimited game experiments, where GAT-DQN outperformed the DQN in every question type, we can also see slightly lower training QA accuracy throughout the training process. Furthermore, we can see that both the DQN and GAT-DQN have very similar training curves, and there is no evidence to suggest that the GAT aided in the convergence of the model as the training curves start to flatline in the same area for both models across all game settings. The exception is the GAT-DQN on attribute type questions when trained on unlimited games with random map, where the training QA accuracy is significantly lower than its counterpart. However, since it is computationally infeasible to overfit the training data in the unlimited game setting, the GAT could prevent the agent from learning some distribution pattern from the environment sampling that does not yield higher accuracy in unseen environments such as the test set.
Conclusions
This study demonstrates the use of Graph Attention Networks in aiding an RL agent's ability to answer a question in interactive text-based environments. Results show that while GATs do not aid in the training convergence of the agent, they can increase the question answering accuracy of agents in an IQA setting, provided sufficient training data with high variability.
Better QA results stemming from greater variability in the training data indicate GATs can create more generalisable agents that perform better to unseen environments when answering questions on locality, existence and attributes of objects in text-based environments. However, providing additional context to the agent using a GAT will not solve the task alone and only aid in an agent's performance, suggesting the GAT's performance is limited by the agent utilising it.
Future Work
Due to time and computational constraints, no experimentation was conducted on how the GAT can aid the other RL agents in the QAit baselines, such as the DDQN and the Rainbow agent. These agents are QAit's best agents for particular map and question types, and equipping them with GATs could prove beneficial. Furthermore, running additional experiments on fixed maps with unlimited games could also be beneficial due to the GAT-DQN's observed requirement of higher training data and variability.
Additionally, one could look into using a different approach to KG construction, which could greatly aid in the performance of the model. Instead of using Stanford's OpenIE along with a set of heuristic rules, one could consider a BERT model trained to construct KGs from state descriptions (e.g. Q*BERT). More recently, WorldFormer was developed as another transformer-based KG constructor, which allows QA models to perform significantly better using its constructed KG over Q*BERT's KGs or rule-based approaches.