Introduction
A corpus is a compilation of text that is used for linguistic research. So a well designed corpus will actually reflect this purpose. South African English which contains many loan words such as "Ubuntu" or "Bakkie" does not have a written electronic corpus available.
Work has been done with developing corpora for South African English but these projects focused on sub varities of the language such as Indian South African English by Peinaar.L , Black South African English by De Klerk.V . These projects also focused on spoken corpora rather than electronic corpora and the corpora were stored using audio recordings and a relatively small sample size.
The need for a South African English corpus is further emphasized by needs of organizations such as the ICE(International corpus of English) for which an SAE corpus is needed as component of thier corpus.The DSAE(Dictionary of South African English) also requires an South African English corpus because their current approach of manually collecting data to compile SAE dictionaries seem to limit the amount of data that can be gathered and also limits the depth to which the analysis of data can take place. This project does not aim to solve the need of these organizations but the requirements posed by these organizations pose the importance for a South African English corpus.
Project Aims
Taking all the factors mentioned above into consideration this project was undertaken to fulfill the following aims:
- Build a corpus of over 1 million words for South African English that could easily be expanded upon in the future and be capable to use for linguistic research by the end of this project.
- Development of an appropriate metadata scheme for the corpus, which will help in adding linguistic context and provenance to the corpus and make it simpler to traverse through the corpus and extract information from it.
- Attempt to fairly represent most sub-varieties of South African English in the corpus.
For our corpus we decided to include the following categories of data:
- News websites
- Political speeches
- Media statements and Advisories
- South African Books(Fiction)
- South African Twitter data
- South African Blogs
Results
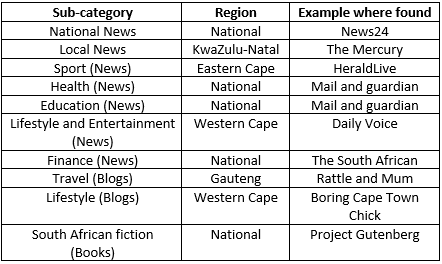
The components of the final corpus and sub categories of data is given in the figures below:
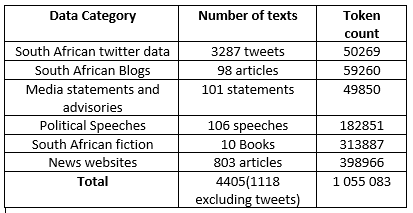
From the results we see that we achieved over a million words for our corpus, though, we do see that data from categories such as Blogs and twitter is significantly less than from news websites, this reason for this is we found that with Blogs and twitter data contained non-English text at times and many tweets and blogs did not pay attention to spelling or grammar. For this reason we included less datat from such sources
Details about the metadata scheme and methods used to achieve the results are given in the project paper
Conclusions
Our final corpus managed to fulfill most of the aims we set out the start of the project, we managed to get a comprehensive corpus of over 1 million words and data from multiple categories where South African English is used.
However, we did not manage to fairly represnt the sub varities of South African English fairly as data from some provinces was not as widely available compared to other more popular provinces of South Africa such as Gauteng or Western Cape
We beleive our current corpus can be used for linguistic research and the metadat scheme implemented will aid in traversing through the corpus and to extract relevant data.