Introduction
Part of speech tagging is a fundamental step in natural language processing. It becomes the basis of all other processing done on text (or speech), such as speech synthesis, machine translations and understanding natural speech. Many have considered this a solved field, given that most taggers reach accuracies of up to 97%, but none of this research is centric to South African English, which has become it's own unique form of English, incorporating many loan words from many of the languages of the regions in South Africa, as well as it's surroundings.
There are papers that make use of taggers, but never addressed the accuracy of them on South African English, or how the accuracies were actually obtained.
Notable papers that reference South African part of speech tagging include Schlünz, Dlamini and Kruger, who used part of speech tagging for the purpose of text-to-speech synthesis for South African languages. Here tagging is important, since some words may be pronounced differently depending on the part of speech they are, such as "lead", which may be to guide someone somewhere, or the soft metal. According to their paper, they achieved a part of speech tagging accuracy of 96.58%, which is identical to the expected results of some taggers.
Louis, De Wall, and Venter applied named entity recognition (A subfield of tagging) to South African texts. Eiselen, used named entity recognition on government domain, focussing on all South African Languages. For English, named entity recognition had an accuracy of 0.42 to 0.67.
Aims
We set out to put existing taggers to the test to determine their efficacy on tagging South African English. If none of the taggers could live up to their claimed accuracies, we begin training of our own tagger, using South African English as our training data.
Our main goal was to determine just how well part of speech taggers perform on South African English. With respect to this, we had several hypotheses.
1. Part of speech tagging will not perform as well on South African English as British or American English
2. taggers will performance measurably better when the register of the text is more formal.
3. Context sensitive taggers will be more accurate in tagging words as opposed to taggers that do not use the surrounding
Methods and Materials
We tested four different taggers against South African English; the Stanford POS Tagger, which boasts an accuracy of 97%, the HunPos tagger, with an accuracy of 96.58%, the TreeTagger with an accuracy of up to 96% and finally NLTK's Averaged Perceptron Tagger, which did not have a paper that stated it's accuracy that we could find.
These taggers were tested against corpus data from Umar Khan. We picked 36 total different articles from different publishers to get a good spread of South African English and different registers. Each of the taggers were tested against the same set of 36 articles. Mainly we used articles from the Mail & Guardian, the Daily Voice, Blue Sky Publications, news24, and various blogs
Results
We got results for each individual article, but for brevity's sake, we compressed them down into the sub-corpora, where each sub-corpus is the publication where the articles came from.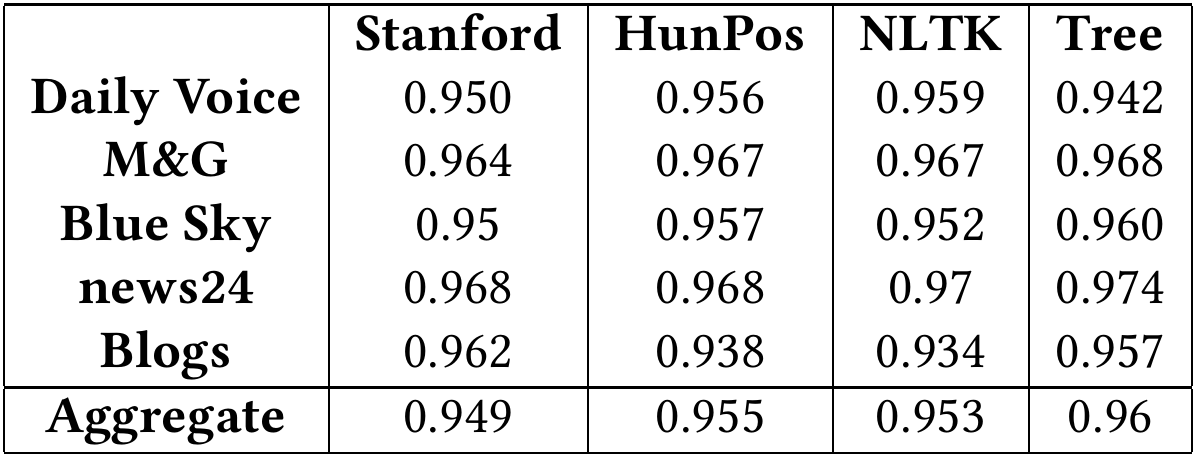
Discussion
Generally speaking the taggers had the most difficulty with contractions and possessive markers ('s). This was due to improper tokenization (the splitting of words), leading to the taggers getting confused. The TreeTagger was the only tagger that successfully tokenized all contractions and possessive markers.
Notably we found that it was extremely rare for words to be marked as foreign, and instead the taggers guessed at the word. Their guesses were usually fairly accurate. The notable exceptions are the TreeTagger and the Stanford tagger. The Stanford tagger marked words as foreign reasonably often, and when it did the following 3 or 4 words were also marked as foreign. The TreeTagger had an additional column of output which included the dictionary form of the word. If it could not find the dictionary form, it was marked as <unknown>. The results showed took those words to mean 'foreign' as well. In Part of Speech tagger efficacy on South African English we included the results when we ignored the dictionary form column. When we ignored <unknown> words, our accuracy increases significantly for some publications, but the aggregate result remained unchanged.
It is worth noting that some of the data from the corpus was not formatted correctly at the time of testing, which may have resulted in lower accuracies for the taggers. A consequence of this could be the reason why contractions and possessive markers were not properly tokenized.
Conclusions
We successfully tested the four different taggers and found that the TreeTagger managed to perform as well as it's original papers reported it to, however the other three taggers fell short. Thus, we can say that some taggers not trained on South African English can successfully tag South African English as accurately as other variants of English.
We did find that the register of text made a difference however. For example, there is a blog that was about South African Slang, and the taggers performed markedly worse in tagging it than other articles, but we believe that part of the reason for this is that the blog presented the words in isolation, as it was introducing the words, rather than the words being used naturally in a sentence.