Exploring a Data Flow Design of CARTA
Background and Context
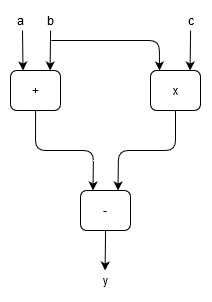
Data flow architecture differs from the traditional von Neumann architecture in that the program commands are executed based on the availability of data instead of a program counter. Thus, the model can be represented as a directed graph (see Fig. 2) with the nodes as the instructions or functions and arcs connecting nodes as the data dependencies. Not only is this representation intuitive, but it can also present some advantages for program design.
The data flow model offers implicit parallel task synchronisation and tolerates memory latency as it processes other instructions while waiting for a response from memory, and thus has these advantage over the von Neumann control flow model. Data flow programs can be composed effortlessly to form more extensive programs by connecting the output of one graph to the input of another, which presents a way of dividing a program into distinct components.
Python Dask is a Python module which provides an implicit data flow environment allows for program development as well as other features like dynamic task scheduling and the use of parallel collections. More importantly, however, Dask allows for the execution of commands on large distributed clusters with minimal input from the developer.
As high performance computing approaches the exascale era, this data flow model is becoming more popular and can be viewed as a sustainable way forward for systems to cope with the expectation of processing more data quicker. This project aims to investigate the implications of making a migration to a data flow model for the CARTA back end.
Aims
To investigate and evaluate the implications of using a data flow model for CARTA, a re-design of the CARTA back-end system was conducted using the Python Dask library. Due to the software engineering design nature of this project, the proposed design could not be quantitatively tested in terms of speedup unless it were to be fully implemented; thus, the design undergoes qualitative testing. The design was evaluated against Dylan Fouche's implementation and the existing CARTA back end to identify any noticeable differences and any significant performance issues or benefits inherent of the proposed design.
Methods

The CARTA back-end implementation along with its most recent Interface Control Document were used to capture the requirements of the system and its various use cases. These use cases were represented in use case diagrams with a CARTA user as the focus actor. Thereafter, more use case diagrams with the CARTA front end as the focus actor were constructed to capture the requirements of the back end. A portion of this use case diagram set can be seen in Figure 3.
The use case diagrams were then used to construct structural (package and design class diagrams) and behavioural (sequence and data flow diagrams) UML diagrams to represent the proposed system design. All diagrams can be viewed in the full technical documentation linked below.
Findings
Shifting the CARTA back-end system to a data flow model offers the benefit of code simplicity. The structure of the proposed system is logical and can be easily extended to include the full functionality of the current back end. The Python language itself leads to simpler code that is easier to understand and follow than the current C++ code, which may make the code base easier to modify and extend if need be.
The Dask data flow environment with the Dask scheduler allows the execution of CARTA operations to be generalised so that the server need only pass the necessary function and data to the scheduler to execute the required operation as seen in the second-level general data flow diagram (Fig. 4). This generalisation will aid the modularity of the back-end server and allows for easy expansion of the operation list with minimal code additions.
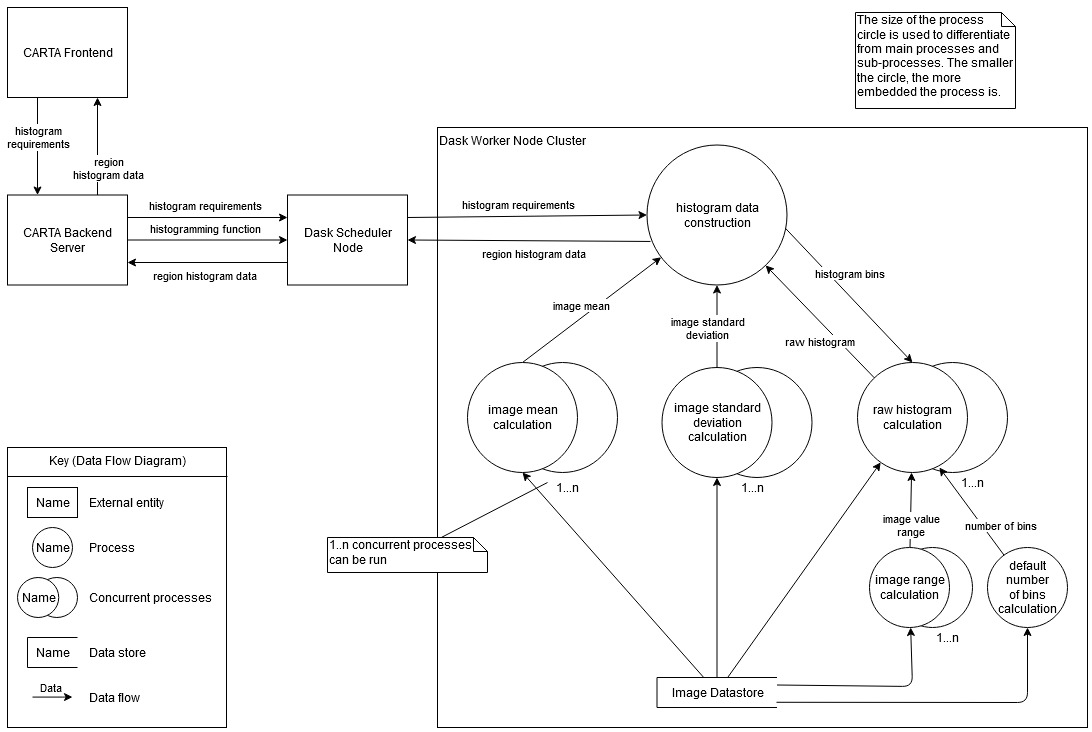
Figure 4 also depicts the operation as it would compute on the cluster as a whole and abstracts from machine specifications of the individual cluster nodes. In a typical control flow environment, the programmer is required to specify which process should run on a which thread, as is the case with C++. Dask, however, handles this duty entirely and need only be supplied the cluster of machines to execute the operation over. Furthermore, this does not restrict the Dask cluster machines to any one type of machine specification, and the back-end operations can potentially be executed over heterogeneous clusters.
While the design itself offers no drawbacks, the shift to Python from C++ may result in a notable performance decrease for some or all CARTA operations as the CARTA system is already optimised to perform these tasks. Nonetheless, the shift to the Dask data flow environment for the CARTA back end is a worthwhile venture. It can provide many long-term benefits for the CARTA system going forward, and Dylan Fouche's prototype lays reasonable grounds from which to start.
 Literature Review
Literature Review