Prototyping a Data Flow Implementation of CARTA
Background and Context
The server component of the CARTA system is currently a multi-threaded C++ implementation, which is widely regarded as a highly performant approach to software development. However, as the image size from modern radio telescopes increases exponentially, a more scalable solution may be required to efficiently analyse and visualise these images in near real-time. We explore the validity of the data flow model as this solution.
The data flow model represents computations as directed acyclic graphs, where there is no program counter and the ordering of instructions is non-deterministic. The asynchronous nature of this model lends itself well to implementation on distributed systems, and this type of implicit parallelism requires no effort from the programmer to prevent deadlocks and other race conditions.
This model is becoming increasingly popular in interactive systems as we approach the exascale era of computing, partially due to its simplicity, efficiency, and manageability. There are many existing tools for data flow computing, which are commonly applied to efficient large-scale batch processing. However, the CARTA system incorporates real-time interaction and computational steering into its use cases, and it is not clear whether existing data flow tools will be able to accommodate this.
The research hypothesis is that it is possible to adapt existing data flow tools to handle this class of high-throughput interactive visualisation and analysis workloads in a performant and scalable manner.
Aims
To evaluate the research hypothesis, we develop prototype back-end components with the Python-based Dask data flow environment. We aim to use these components to gauge the performance and scalability of a data flow based CARTA back-end. The prototype back-end developed will serve as a proof-of-concept and may be a starting point for the development of a full production-ready data flow back-end.
Methods
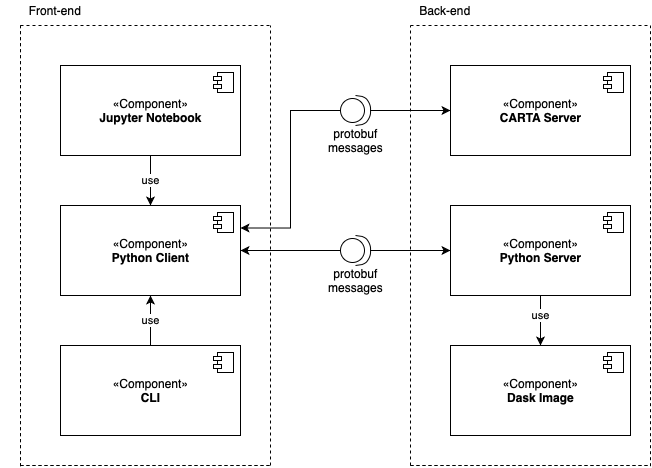
We implement a Dask image class that will read in an astronomical image and store it in a Dask collection which gets chunked and persisted to distributed memory. We use Dask's wrapper functions for a range of SciPy and NumPy behaviour to perform distributed computations over this image. We implement a Python server with websockets that mimics the behaviour of the CARTA back-end under a certain set of functions.
We implement a client that can connect to and exchange messages with either our Python server or the CARTA back-end. These messages are defined in a shared repository of protocol buffer messages. We then use this client firstly to compare the output of the CARTA system and our system to prove correctness, and secondly to measure the performance of our solution versus CARTA under a range of conditions.
Findings
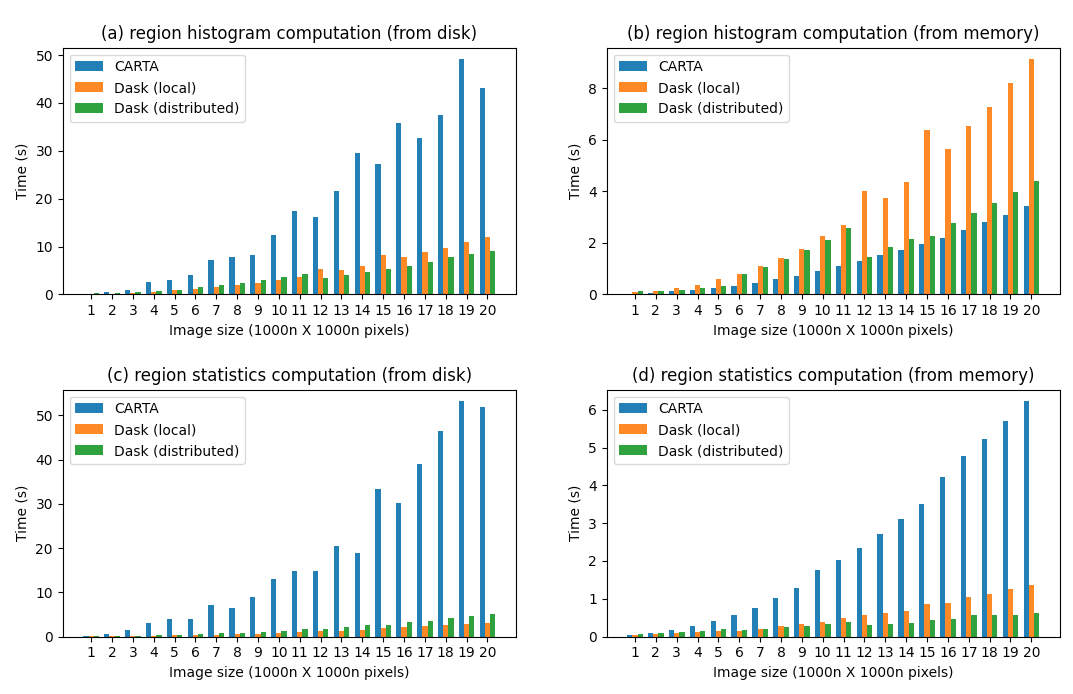
Once correctness testing showed that our implementation behaves correctly, we conducted performance testing under a range of different back-end functions and operating conditions. The results of these tests reveal that Dask is significantly faster than the CARTA back-end in the best case, and about the same in the worst case. Furthermore, since Dask can distribute work across an arbritrarily large (and potentially hetrogeneous) cluster of machines, it is far more scalable than the current implementation.
Thus, we find that the move to a data flow architecture may be beneficial for CARTA.
 Literature Review
Literature Review
 Code Repository
Code Repository