Collector
– Alex Olivier
Introduction
This research project forms part of the larger project, Archiving Archives, depicted in Figure 1. This archive collector specifically addresses the archive retrieval part for this Archive of Archives, highlighted in blue in Figure 1. In practice this research involved the building and then experimentation on a system that created “archive snapshots”, that visually and functionally replicate archive websites, of already available archives, created using popular archiving toolkits, which can be included in the Archive of Archives. The goal of the experiment was to investigate the degree to which this would be possible.
 Figure 1: Archiving Archives Model
Figure 1: Archiving Archives Model
Research Question
My research question: “To what degree can the data of archives, created using popular archiving tools, be scraped to produce Archive Snapshots?”
Methodology
To test my research question, a system to extract data from online archives, generated by specific archiving toolkits, more specifically, a custom Web scraper, was developed. A pilot questionnaire to gather results around the snapshot was used; followed by a second questionnaire. The questionnaires comprised participant background and task related questions to visual comparisons and functionality, conducted by the participants. The data was then analyzed and split into suitable categories measuring specific degrees.
Development
The archive collector, used to create a snapshot of the online archive, comprised of a custom web scraper. The web scraper was developed using an agile approach in Python for its fast prototype development speed, easy string manipulation, threading support for I/O bound tasks, object-oriented paradigm, and well documented libraries. Notably, the Beautiful Soup library, capable of parsing XML and HTML files, was used to identify resources and domain links. The scraper’s class diagram is represented in figure 2 below.
 Figure 2: Scraper Class Diagram
Figure 2: Scraper Class Diagram
Development started with shallow scrapes on statically generated sites and later progressed to deeper dynamically generated sites. This was necessary as some archiving toolkits, such as DSPACE are dynamically generated. Once all HTML pages and related site and archive resources were identified and scraped, they were modified in order to save an archive snapshot as flat files that could be used locally and ingested by the archive ingestor, highlighted in red in figure 1.
Results
The questionnaire to assess the degree that archives, created using popular archiving tools, could be scraped, was completed by 21 participants. Three aspects of DSPACE and EPRINTS generated archive snapshots were tested. Snapshot visual accuracy, functionality, and usability.
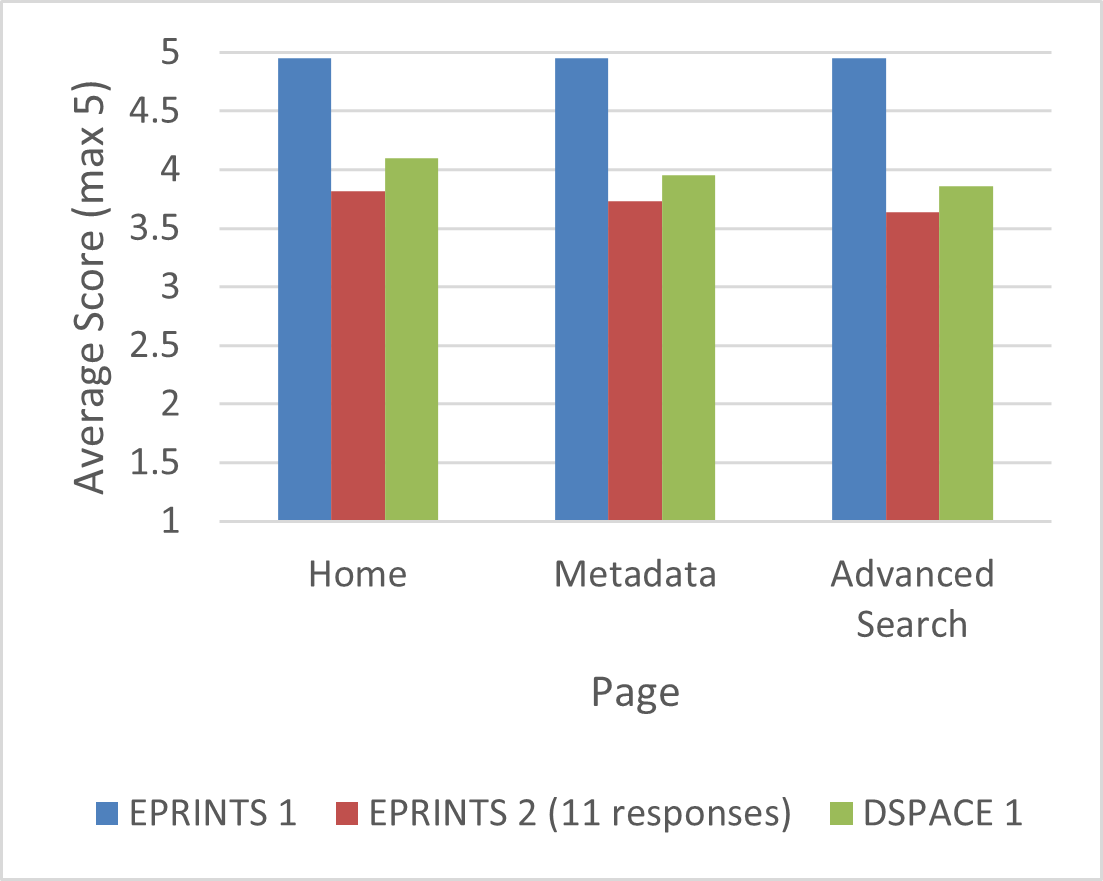 Figure 3: Visual accuracy graph of archive snapshots
Figure 3: Visual accuracy graph of archive snapshots
Figure 3 shows great visual accuracy results for both DSPACE and EPRINTS snapshots on three separate tested pages.
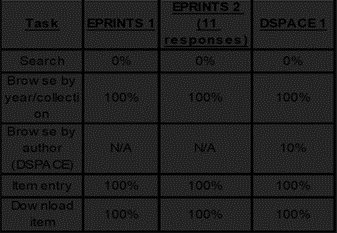 Table 1: Percentage of tasks completed
Table 1: Percentage of tasks completed
Table 1 indicates great results for snapshot functionality except for the use of the search functionality and browse by author on DSPACE generated archives. The search functionality could not be preserved due to its server dependance and browse by author was not preserved as only a subset of query strings, used to generate dynamic HTML pages in DSPACE archives, was supported.
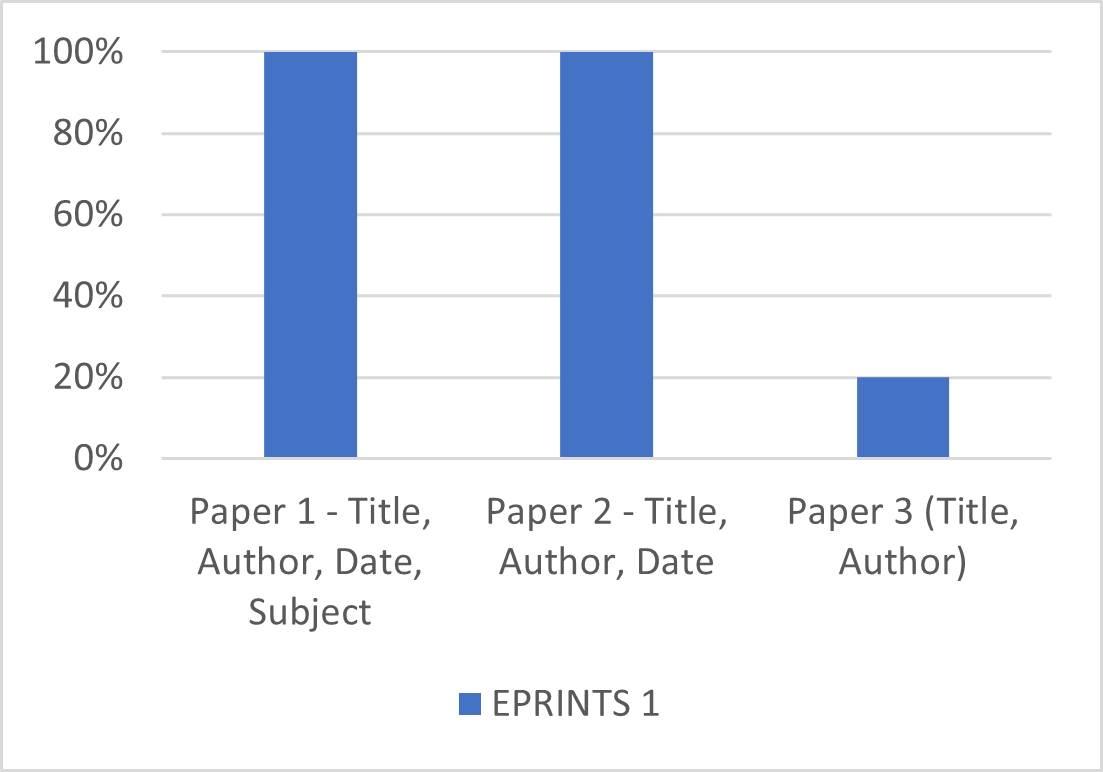 Figure 4: Percentage of papers found – EPRINTS 1
Figure 4: Percentage of papers found – EPRINTS 1
Snapshot usability was heavily dependent on the amount of knowledge around an item that a user was looking for. While the snapshots could be browsed by many categories, finding a specific paper proved difficult given the missing search functionality that most users tried to use first, but could not be preserved.
Conclusions
The results indicated that the archive collector could visually preserve archives to a high accuracy and preserve most functionality. However, usability is heavily use case dependant and suffers from the missing search functionality. Future work lies in the testing of more popular archiving toolkits and the outcome of the integrated project, of which features could solve the snapshot usability problems.