N-gram Language Models
N-gram models are one of the simplest widely used language models, which
perform well across a variety of language modellings tasks. We examined
the performance of a traditional n-gram language model and a feedforward neural network
language model (FFNNLM), which can be considered a special case or extension of a basic n-gram model, on a selection of low-resource South African languages, namely isiZulu and Sepedi.
By evaluating each of these types of model’s performance and comparing their performance against
each other, we aimed to determine whether there is a significant difference between the two models in terms of performance.
Models
Basic N-gram Language Models
N-gram models make use of the approximation that the probability of a word depends entirely on the previous (n-1) words. This approximation relates to the idea of Markov models, which states that we can predict the probability of some future unit without looking too far into the historical context of that future unit. This approximation relates to n-gram models in terms of future words and their history. For our n-gram language models, we used modified Kneser-Ney smoothing.
Feed-Forward Neural Network Language Models
The first type of neural networks introduced to the field of language modelling was Feedforward Neural Networks (FFNNs), which adopted the paradigm of supervised learning, which refers to output targets being provided for each input pattern, which is followed by explicitly correcting the errors of the network. In contrast to traditional count-based n-gram models, FFNNs estimate probabilities of words and sequences via the use of a neural network, rather than using smoothing methods to estimate probabilities. Although FFNNs differ from n-grams in terms of probability estimation, both models are based on the Markov assumption.
Results
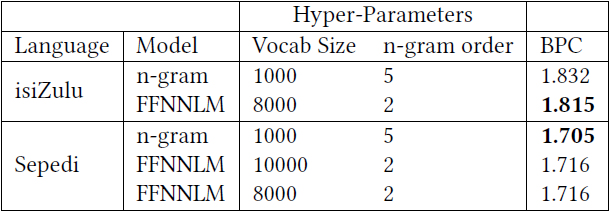
It must be noted that although Sepedi language models, across both types of language models tested, achieved significantly better performance metrics than isiZulu language models, this was likely due to roughly half the number of tokens in the training data available to our models for the language of isiZulu when compared to the number of tokens in the training data available to our models for the language of Sepedi.
Conclusion
In this study, we implemented, optimised, and tested many language models of two different types, namely traditional n-gram models and feedforward neural network language models, on the low-resource languages of isiZulu and Sepedi. Both types of models were evaluated and then compared against one another, in terms of their performance, which was measured in bits-per-character. Our results show that for both the languages of isiZulu and Sepedi, in low-resource conditions, traditional n-gram models and FFNNLMs performed similarly in terms of performance, however, the most accurate FFNNLM performed slightly better than the most accurate n-gram model when trained and evaluated on the language of isiZulu. The opposite is true when these models were trained on the language of Sepedi, where the best performing traditional n-gram model slightly outperformed the best performing FFNNLM.