Long Short Term Memory Models
The use of Recurrent Neural Networks (RNNs)
has been shown to produce high performing language models on
English and other high resource languages. We examined
the performance of Long short term models (LSTMs) and Quasi
Recurrent Neural Networks (QRNNs) and their applicability to
South African low resource languages.
We aimed to determine whether the increased complexity of modern techniques sufficiently
improves on a more basic LSTM model when applied in South Africa Language. Specifically across
different sized
isiZulu and Sepedi datasets.
Models
Basic LSTMs
Long Short-Term Memory (LSTM) models are a popular variation on the Recurrent Neural Network (RNN) architecture allowing for longer term dependencies to be modelled effectively. An LSTM network expands on the traditional RNN architecture by introducing the "context" or "memory" vector which is passed between timesteps in addition to the usual hidden layer vector. Put simply the LSTM context vector encodes long term dependencies by allowing the model to explicitly "decide" to add or remove information from the context vector at each time step. However the Basic LSTM models are prone to overfitting without sufficient regularisation.
AWD-LSTMs
The AWD-LSTM is a variant on the standard LSTM architecture which incorporates the improvements to the regularisation techniques proposed by Merity et. al. These include the Variational Dropout and Drop Connect techniques above as well as Variable length backpropagation sequences, Embedding Dropout, Weight Tying and Activation and Temporal Activation Regularization. These regularistion techniques allow much larger models to be trained for longer without overfitting the data in the same way a more standard LSTM would be prone to do. This improves performance on the unseen/test data.
Quasi Recurrent Neural Networks
Inspired by the RNN models, Quasi-Recurrent Neural Networks (QRNNs) allow for parts of the typical RNN architecture to be computed in parallel. This can allow for much faster training of the models whilst maintaining similar or better performance that a conventional RNN architecture, including the AWD-LSTM.
Byte Pair Encoding
Byte Pair Encoding (BPE) presents a method to combine the benefits of character and word level modelling to attempt to offset their respective downsides. Chracter level encoding requires only a small number of tokens (purely the letters and symbols that appear in the text), however this means that every word predicted require multiple tokens reducing the effective "memory" a model can have of past context as more tokens (characters) must be modelled. Word level encoding by contrast, encodes each word as a separate token. This means a model can "remember" far further back for the same number of tokens. However this means every word in the language must be stored as a separate token leading to extremely large vocabulary sizes, or less common words must be replaced by "out of vocabulary" tokens during preprocessing. This is only exacerbated in agglutinative languages such as isiZulu and Sepedi (wherein the words within the language are made up by combination of smaller morphological units or "sub-words"). BPE groups characters into single tokens resulting in shorter token sequences than than character-level tokenization and a smaller vocabulary size than word-level tokenization. Additionally because BPE encoders always have at least the tokens of the character level model, There is no need for out of vocabulary tokens. Thus BPE encoders enable an "open vocabulary" model as even unseen words will be correctly encoded.
Results
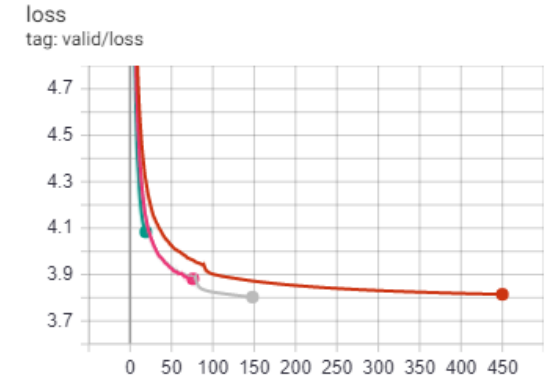
For all models across the datasets, although longer training times were needed to produce the best possible results, the vast majority of the models training improvements were completed within the first 3 hours of the 12 hour training cycles used. This suggests that the models could continue to improve if there was far more training data available. This is expected as it is well known in other language modelling tasks that this is a relatively small amount of training data to be working with.
Conclusion
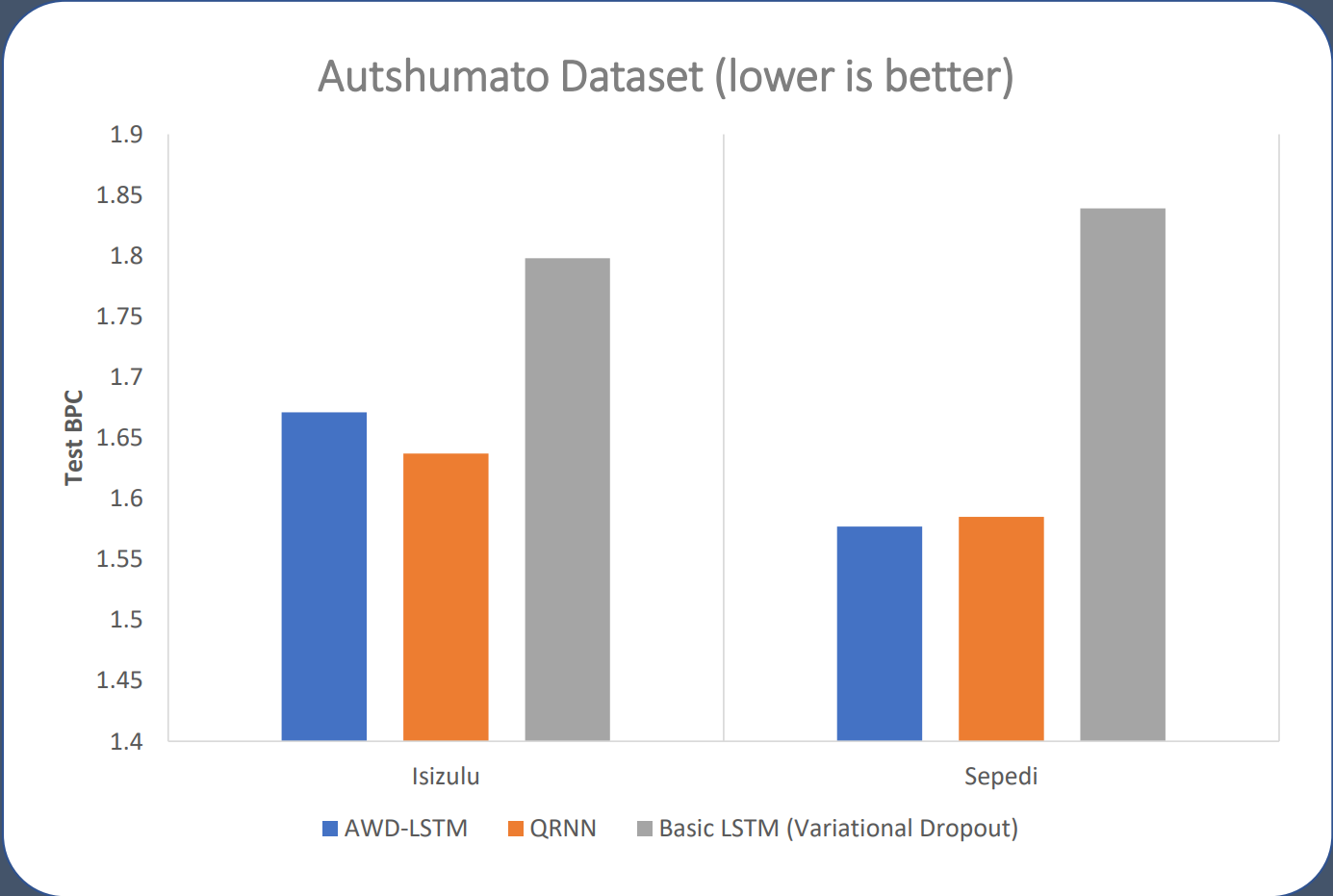
The conducted experiments demonstrated that the improvements in regularization techniques and model architectures for RNNs over the standard LSTM model continue to improve model performance significantly when applied to African languages such as isiZulu and Sepedi. Furthermore the relative improvements of QRNN models over the AWD-LSTM models seen on our languages are consistent with those seen in English tasks.
These relative performance improvements are consistent across a range of dataset sizes in both languages. This suggests that further improvements in RNN based language modelling would likely be directly applicable in low resource African languages going forward, without the need to repeat the long testing process needed to optimise these new models.
Additionally we show that the use of BPE to allow for open vocabulary language modelling is an effective method to account for the large word level vocabulary sizes of agglutinative African Languages