Virtual Panning
Tracking Component
By Chris Pocock
Introduction
For humans, recognising and detecting moving objects can be a simple task. However, computerising this process requires complex solutions. As a result, there are a number of different approaches to the problem of object tracking. The choice of which approach to use is largely dependent on the context of the problem.
The tracking component of the VIRPAN system is responsible for detecting a portion of a presenter over multiple frames of video. The component hopes to replace the need for a manual cameraman or any user input by doing this automatically. In doing this, the component forms part of a system that offers a cost-effective solution to the problem of automated lecture recording.
Aims
The primary aim of the tracker was for it to be a self-contained system that could detect the position of a presenter in a video file and write their coordinates to a text file.
Regarding speed, the CILT required the processing time of the VIRPAN system to not exceed three times the length of the recorded lecture. This was needed to make the intended use of the system as an educational tool viable. Since the VIRPAN system consisted of three components, the tracker aimed to process videos in under the duration of the video being processed.
Another aim was for the component to track the presenter as accurately as possible. The accuracy was important as it determined the coordinates that the panning component would use. It needed to be accurate enough for the panning component to produce sensible output.
Lastly, the tracker aimed to be robust to varying environments and conditions. This was so that it could be used in different lecture theaters at UCT. It needed to perform similarly despite different lighting conditions, presenter behaviour or room features. It aimed to track the presenter in scenes with noise, clutter or occlusions of the presenter.
Component Overview
The component used a frame differencing approach as a basis and was divided into three steps; pre-processing, filtering and analysis. These three steps are repeated as long as there are frames from the stitched video that have not been processed yet.
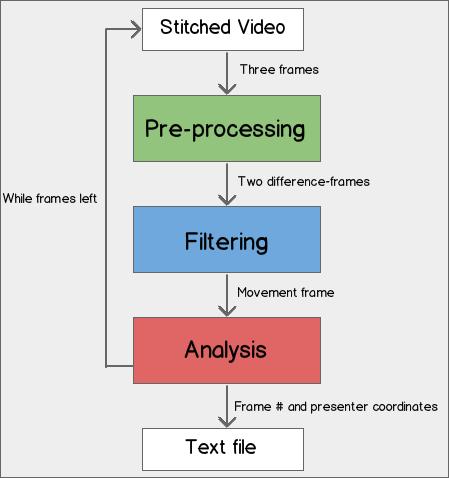
The pre-processing step captures and prepares three consecutive video frames for frame differencing. It then produces two difference images from the three prepared video frames.
The filtering step filters the two pre-processed images to create a filtered image for analysis. In this context, filtering means enhancing the effect of events such as presenter movement and reducing the effect of interferences such as noise or clutter.
The analysis step analyses the filtered image to determine if a significant presenter movement has occurred. The resulting coordinates of the presenter are written to a text file along with the frame number they were detected at.
Results
The proposed tracker was found to be a viable component of the VIRPAN system. Testing showed that the aims of the tracker had been realised, with some aims realised to a greater extent than others.

With regards to speed, the component met its aims and the requirements of the CILT, consistently processing videos in roughly a quarter of their duration. The accuracy of the component was high enough to track the presenter and produce sensible input for the panning component. Tests showed that the component was robust to varying conditions and events. However, the component was tested on recordings supplied from a single lecture theater, so knowledge of the component’s adaptability at large is limited.