IsiZulu NC Tagger
What is isiZulu Noun Classification?
The IsiZulu nouns each belong to one of 15 isiZulu Noun classes, a trait which is shared amongst all Bantu (as isiZulu is typically linguistically classified) languages. Each noun has a prefix, which may or may not be unique, that indicates which noun class that noun belongs to.
But how do you determine the right key for your keyhole when most of them look the same to your eye? This is the problem that inspired the need for alternative identification methods that do not use the identifying noun prefix alone for isiZulu noun classification, where a single prefix may belong to multiple classes, and knowing the boundaries between words and their stems may be impossible.
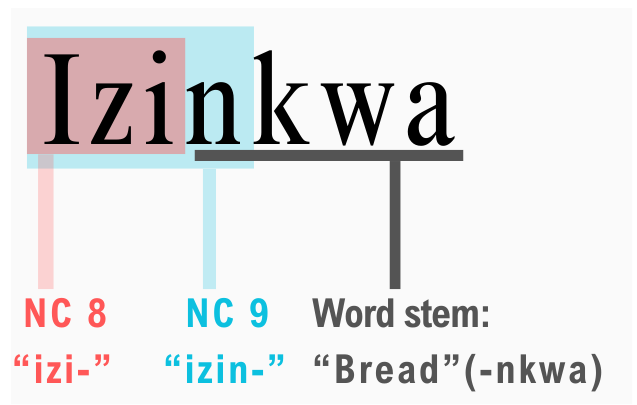
In the same way that we use “is” or “are” based on whether our subject is “dog” or “dogs”, the categorisation of the nouns in a sentence determine the concordance of the rest of the words in it. Noun class identification is a tricky, but crucial, problem to resolve for correct grammar in the sentence realisation step of the NLG pipeline, for tagging lexical properties of words in databases like Wikidata, building annotated training corpora for data-driven tasks and more.
What is the "Combined Syntactic-Semantic Method?
Noun classes can be identified using:
- Noun prefix and concord prefixes [Syntax]
- Concepts attached to that noun class [Semantics]
Why reproduce the Runyankore method, specifically?
An excellent question! It was the first and only attempt at disambiguating those non-unique noun class prefixes for any language of the Bantu family. Morphological analysers like ZuluMorph, or CRF-based, data-driven part-of-speech taggers achieve similar accuracies for their overall tasks, but the accuracy of the noun class identification specifically is unknown, they may have limited cross-linguistic compatability, or only accept sentence-level data. There is therefore significant room for improvement. The Runyankore method is therefore one that we hope to build on and adapt for this crucial task in other languages with a noun class (“NC”) system.Our exploration of cross-linguistic reproducibility has three aims, to determine...
Aims
The Extent of Direct Reproducability
...If the specifications for the Runyankore method and materials can be recreated exactly for isiZulu
Conceptual Reproducability of the Original Conclusions for Runyankore
...If we can recreate a similar conclusion for isiZulu that using the combined syntactic-semantic method outperforms using either syntax (noun and concord prefixes) or semantics (the noun concepts associated with each NC) alone for identification
Tailoring Training Data for Optimal Results
...And if adjusting the qualities of training data can enhance classification accuracy in resource-limited contexts by altering data quality, labelling depth, annotation quality, and corpus size.
System Implementation
What we were working with...
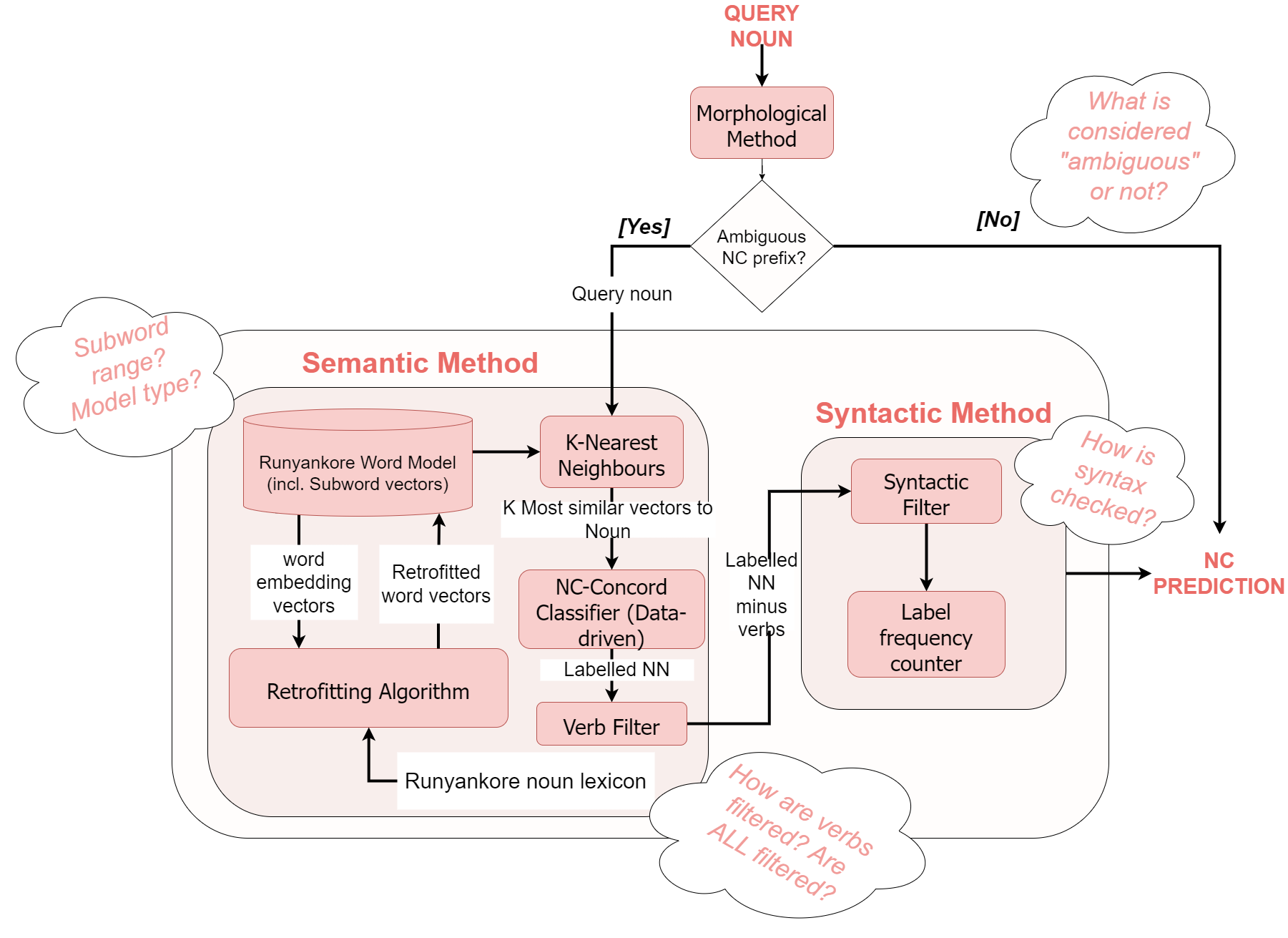
...And what we did with that:
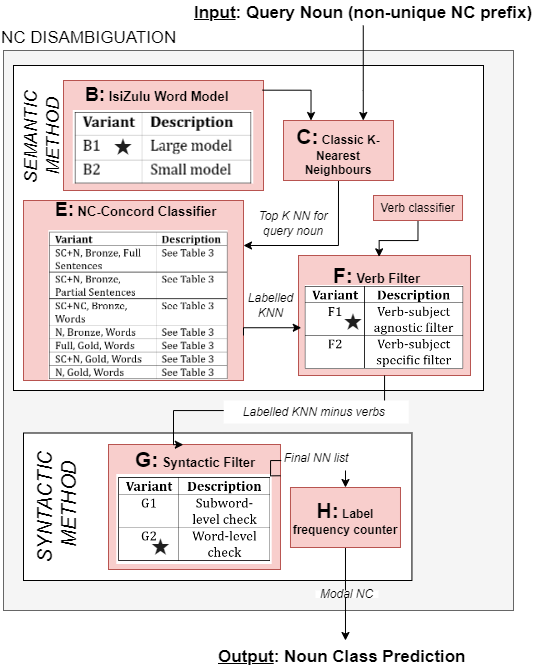
We created multiple versions of some components to account for ambiguity in the original implementation that could not be deductively resolved. We created seven baseline versions of the NC-concord classifier, which drives the tool’s predictions, to test what data qualities would produce the best results. A star in the diagram alongside indicates a "base" version of a component, used across the seven baseline versions.
The large, base word model (starred) was based on the isiZulu National Corpus (~1 million sentences). We used an automatic part-of-speech tagger to create a labelled and unlabelled corpus based on over 100 000 web-crawled sentences, and enriched the labelled version with subject concord labels via rule-based annotations. This formed the basis of our "bronze" data. Because high quality, gold-standard annotated corpora are labour intensive to create, the tool's success in the case of inaccurate training data would hint at more scalable implementation than that of the original Runyankore tool, which was atypically highly resourced.
Evaluation
Evaluation was conducted against a set of nouns of over 700 with their ground-truth noun classes.
Our experiments were along two line of enquiry: testing different possible interpretations of component implementations to better ensure faithful reproduction, and to answer what tailoring of the training data, if any, leads to superior final noun class prediction accuracy, For the NC-concord classifier component, comparable training data was impossible to recreate for isiZulu, so we substitutes this with seven different versions of the training data to produce seven "baseline systems".
Reproduction of System Components
Where important details were omitted from a component's implementation description, we inferred the most likely course of action from implicit details. This “base” version was tested against an alternate, but less likely, interpretation (a “variant”) to ensure faithful reproduction. The "base" components are used in the baseline system versions. We tested the base systems with each "variant" component and compared the variant and base component performance using the average and maximum final accuracy across two testing datasets.
Results
In all cases, the “base” version outperformed the variant implementation developed. However, the variant word model (10% of original training data) narrowly underperformed compared to the larger model. This, combined with the composition of the Runyankore word model (a big model, but small vocabulary with a high degree of inflectional variety in word form) may suggest that a high degree of morphological variety that strengthens good subword embeddings is more useful than a large word stem vocabulary.
What about the data?
The best performing characteristics were not absolute. It was possible to produce good performance with both a high volume of data with less accurate annotations, and a very small gold standard annotated corpus which is promising for reproduction in other languages. Simple, short sentences outperformed complex sentences or word-level data, especially for lower quality labels. Data having highly accurate annotation had a greater positive effect than a large corpus size with less accurate data. Lastly, using fewer labels in the training data yielded better results for gold-standard data, but not for bronze. Because the bronze data yielded good accuracies for data-levels that give more context as opposed to word level data, it may suggest that that additional sentence context aids in strengthening morphological or grammatical inferrences in training, thereby reducing error.
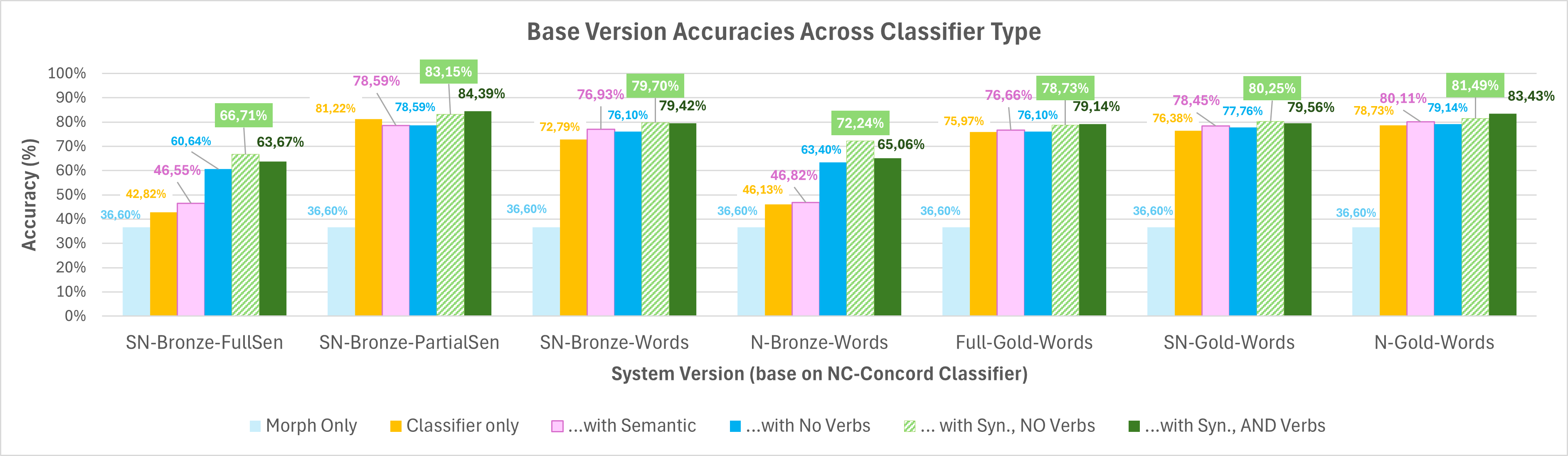
So, relative to our aims that means...
We were able to recreate the result that the syntactic-semantic method outperforms using either alone across multiple different reproductions and training data types, which is extremely promising for succesful conceptual reproduction for different languages with varying natures of existing annotated data available. The method may not eventually outperform stronger data-driven classification as this was not explored in the original paper, and in our case the difference in improvement the method gives compared to classifier-only tagging is smaller as the quality of that increases. However, it still acted to improve on the NC-concord classifier's accuracy, showing its potential merit as improving accuracy of classifiers through error reduction.So, what was the verdict overall?
While replicating the original system's data and methodology proved unfeasible due to data constraints and missing implementation details, the NC identification improvement achieved by the combined method was highly reproducible across all versions of the system, even when as little as 3% of the labelled training data was used for a final highest accuracy of 84.3%. In part because of smaller returns as the quality of the data-driven NC classification component increased, we deduced that the strongest merit of this method may be as a form of error-reduction to improve the performance of data-driven NC classification.
Using a small quantity of accurately labeled data to generalize NC-concords to their noun classes is highly effective in handling morphological variability; short sentences balanced word concord variability and sentence context. This indicates promise in generating 2-3 word sentences labeled at the general NC level, as introduced by Gilbert and Keet for isiZulu, and reproducing the method thereon which we leave as future work. We contribute a first NC-identification tool for isiZulu with up to 84.39% accuracy, and encouraging evidence supporting its conceptual reproduction for other Bantu languages.