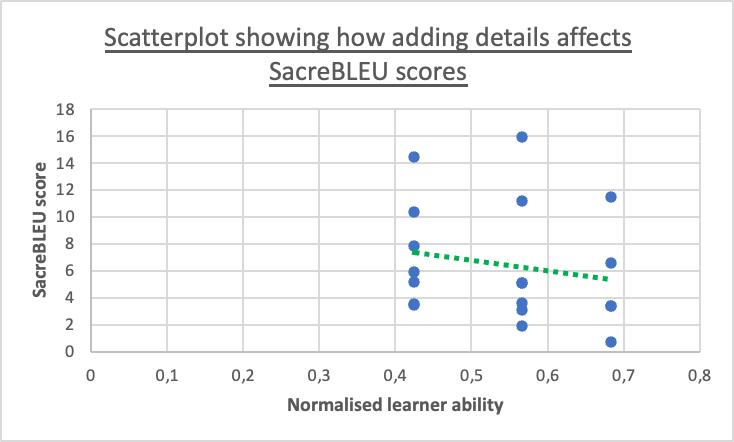
This table shows how the SacreBleu score decreases as the normalized learner ability increases, which means that the LLM is injecting more details in the sentences. This plot is for the GPT-3 model. The normalized learner ability fits the original learner ability value between 0 and 1 and also inverts it so that when the learner ability is high, the normalized value is low, and vice-versa.

Introduction
The Natural Language Generation Algorithm (NLGA) is the last component in this proof-of-concept adaptive learning system. After the learner has answered the asked questions and the system is done processing the answers to quantify and represent the learner’s knowledge gaps in the form of a weighted knowledge graph, which we call the ‘learner knowledge model’, this component takes that as input and represents it in a natural language-written document. The weighted edges of the knowledge graph are what we call the ‘learner ability’ and represents the learner’s knowledge on said topics. We use the learner ability to adjust the amount of detail added in the document so that its usefulness for the learner is maximised as they get more comprehensive notes on topics they did not understand. The modularity of this algorithm allows it to be smoothly integrated into the whole project as well as being used as a standalone algorithm for knowledge graph-to-text generation.
Research Aims
The research aim of this paper is to find a method to create more detailed and human-like descriptions of knowledge graphs, represented in the form of triples, while maintaining a focus on the content. A triple is in the form of < subject, predicate, object >, which is a way to express knowledge graph data. The predicate normally represents an edge while the other two are nodes.
Methodology
The reviewed literature showed that current methods, in addition to being complex and hard to implement in all scenarios, produced only a simple description of the triples. Since the NLGA component was especially being designed for an adaptive learning system, we needed a method that could define the entities in the triples, where needed, to provide more context in addition to producing a sensible textual verbalisation of the triple. The NLGA component uses a large language model (LLM) and prompting as its underlying technology to generate sentences. Throughout this paper, we tested 3 different LLMs for this task and our evaluation results indicated that out of the three tested, GPT-3 was to best suited. The learner knowledge model is provided in a CSV format which from which the triples and the corresponding learner ability is extracted. Each triple is embedded in a prompt template and the learner ability is used to configure the max_tokens parameter of the LLM, effectively setting the amount of detail needed per triple.
Evaluation
Two types of evaluation were used to evaluate this component, metric and human evaluation. The metric evaluation was used to determine which model generates the most-detailed sentences out of the three tested. The benchmark included; SacreBLEU, ROUGE-L and METEOR. These metrics give high scores if the generated sentence matched to a certain reference text but we showed that in our situation, if these metrics give a low score, the generated sentence contains more detail, although unverified. The human evaluation was used to verify whether the added details by the model highlighted by the metric evaluation, were actually useful and contributes to achieving our aim. This was in the form of a survey which evaluated 4 different aspects; Quality of generated sentences, Relevance and focus, human-like quality and information content of the generated descriptions.
Results
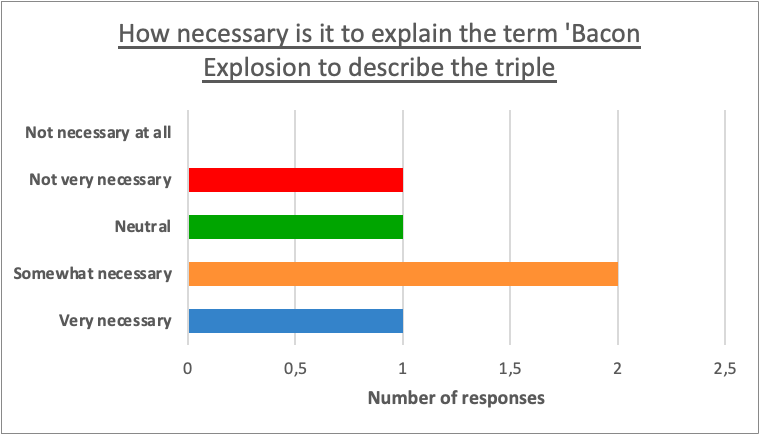
This bar chart is an extract of the result we obtained from a user evaluation done to verify the validity of the added details. This shows that the added details to describe ‘Bacon Explosion’ were appreciated by the human evaluators and were considered overall necessary.
Conclusions
Through the metric evaluation, we identified GPT-3 as the LLM generating the most amount of detail. The human evaluation showed that the sentences were found to be grammatically and factually correct albeit not very human-like. The details in the sentences were also found to be valid and necessary for properly understanding the facts described by the triples. Overall, our work show that the use of LLMs like GPT-3 for generating descriptions of knowledge graphs is a relatively easy to use method than can form more detailed sentences out of knowledge graphs. The use of this method in the creation of an Adaptive Learning System was found to be beneficial. The limitations of this methods are that should the LLM be run on a local system, a powerful modern GPU is required and should the Adaptive Learning System need to generate a very lengthy document, the LLM will take a considerable amount of time.
Future Work
Based on what we discovered throughout this research, this method of knowledge graph to text generation needs to be tested with more models to find the one that strikes a balance between the use of resources and quality of desired output. The need of a method to improve the human-likeness of the sentences was also outlined by the conducted evaluation. Since education is an international subject, the need of adaptive learning materials in other languages is also in serious demand thus the need to investigate a translation task for the informative document.