Project Aims
The aim of this project is to compare baseline Neural Machine Translation models translating from English to IsiXhosa and from English to IsiZulu against model trained using data augmentation techniques. The first data augmentation technique that we employ makes use of target-side monolingual data to augment the amount of parallel data via back-translation (convert target side language into source side language) and the second technique involves training a multilingual model on a joint set of bilingual corpora containing both IsiXhosa and IsiZulu language.
Background
What is Neural Machine Translation?
Neural Machine Translation (NMT) is a recently introduced paradigm that has achieved state of the art performance outperforming traditional machine translation methods. It models the machine translation process by using a single, large Neural Network that takes as input a sentence and outputs its corresponding translation one element at a time, in an end-to-end fashion. This allows all parameters of the model to be simultaneously changed to maximise translation performance.
Encoder-Decoder model
Most Neural Network translation relies on the encoder-decoder network. The encoder in an encoder-decoder or sequence-to-sequence network takes an arbitrary length input and produces a fixed-length vector representation of the input, as output. This output is known as the context vector which is used by the decoder to produce a variable-length translation of the input
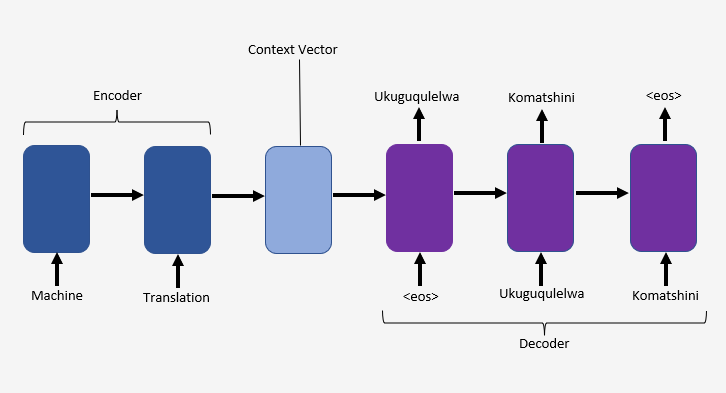
Attention Mechanism
With the encoder and decoder separated, the decoder only knows about the source text through the context vector. The Neural Network must compress all the information from the source text into the final state of the encoder. This makes the Neural Network unable to give correct translations for longer sentences. The attention mechanism proposed by Bahdaunau et al. solves this issue by making all information from all the hidden states in the encoder available to the decoder instead of only the last hidden state. This is achieved by taking a weighted sum of all the hidden states in the encoder and creating a fixed-length vector from the weighted sum. This fixed-length vector is then used by the decoder.
Transformer Architecture
While Recurrent Neural Network and other sequence-to-sequence models have been the state of the art in the machine translation paradigm, their inherent sequential nature prevents them from being parallelised. This causes their performance to degrade over long sentences. In this study we used a new model architecture, transformers, proposed by Vaswani et al. relying solely on attention mechanism which allows more parallelism.
Data preprocessing and model training
Subword Segmentation
Bantu languages have a rich noun class system and a complex structure due to their agglutinating morphology. This makes it hard for Neural Machine Translation models to handle such languages and requires mechanisms to go below word-level. As such, in this study we make use of Byte Pair Encoding sub-word tokenization to break large vocabularies into smaller subword units which can be easily interpreted by Neural Translation models. In addition, this help translates rare words more accurately and generate words that were not seen during training. This technique of using subword units to encode rare words was proposed by Sennrich et al. Their main goal was to enable neural machine translation models to generate translations for words that were not present in the training set but instead to use known subword units when translating unknown words.
Baseline Models
English to IsiXhosa and English to IsiZulu baseline models were trained with different hyper-parameters. The best performing model was then compared with subsequent models.
Backtranslation Models
To convert the target side monolingual data into additional parallel data a reverse machine translation model, that translates the target side language into the source side, was trained to back translate the target language into the source language. Another model was then trained on these augmented parallel data.
Multilingual Model
A multilingual model with English as the source language and IsiXhosa and IsiZulu as target languages was trained and some hyper-parameter tuning was performed to get the best performing model. we add an artificial language token at the beginning of the input sentence to specify the target language. This process allowed multilingual translation without the need to modify the Neural Machine Translation architecture.
Results
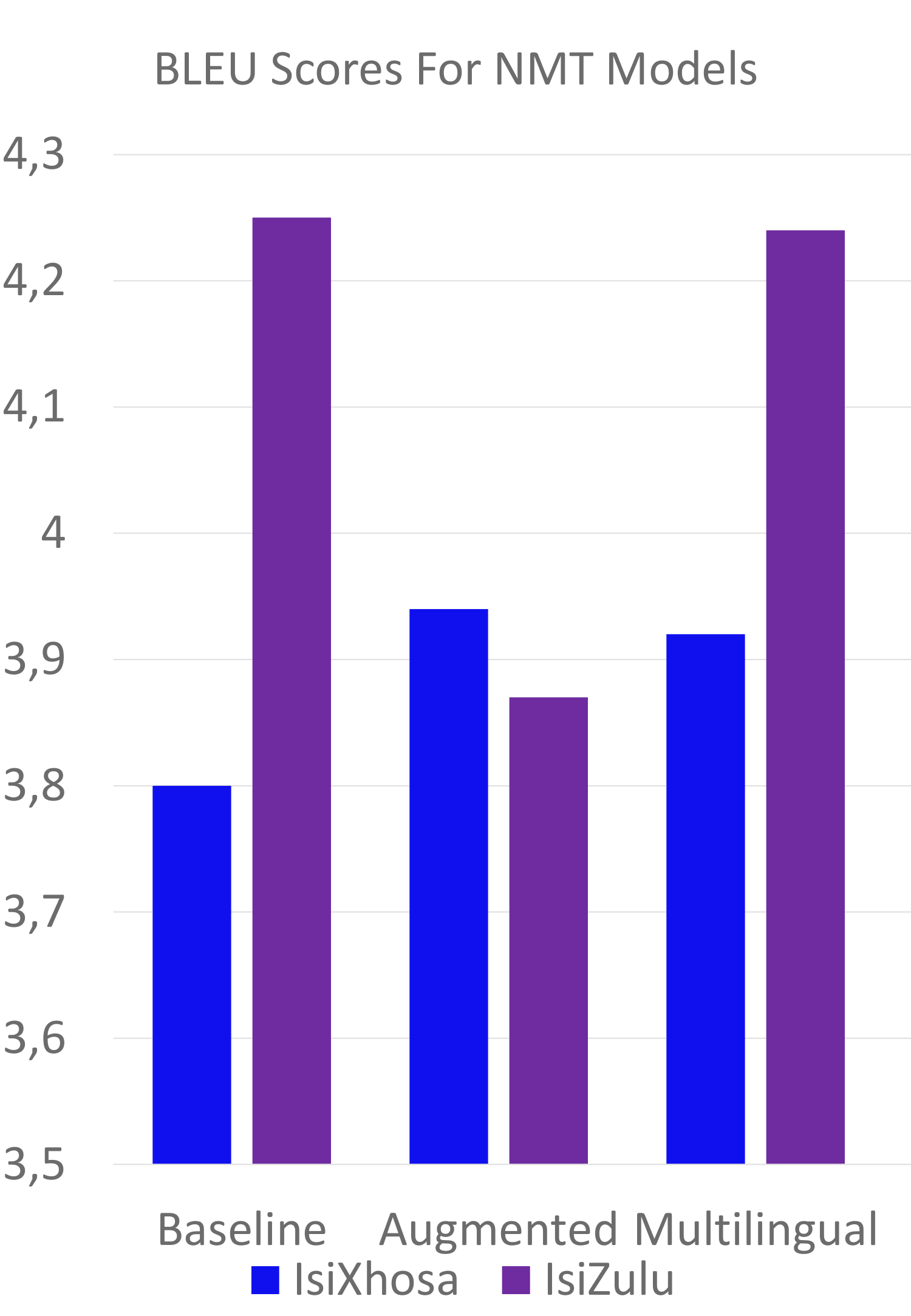
The English to IsiXhosa model trained on augmented parallel data gained a 0.14 increase in BLEU scores over the baseline English to IsiXhosa model. The English to IsiZulu model did not show any improvement over the baseline model. However, this model is seen to have overfitted the training data. When the model is trained on a larger parallel dataset obtained as a result of the back-translated monolingual data, it takes longer for the model to overfit the training data. This could have resulted in an increase in BLEU scores over the baseline model if a different evaluation set was used to evaluate the baseline model and if the model was trained on a larger dataset. Using a small subsample size of the monolingual data resulted in the machine translation model trained on augmented parallel data performing worse than the baseline models. However, as the subsample size is increased the performance of the models increase as well. The English to IsiXhosa and IsiZulu multilingual model gained a 0.12 increase in BLEU scores over the baseline English to IsiXhosa model. The English to IsiXhosa model trained on augmented parallel corpora outperformed the multilingual model with a BLEU score of 0.02. The Multilingual model for translation from English to IsiZulu outperformed the augmented parallel corpora by 0.37 BLEU points.
Conclusions
In this study, we used the state of the art Transformer Neural Machine Translation to compare the translation performance of baseline models with models trained using two different data augmentation techniques on low resource South African languages namely, IsiXhosa and IsiZulu. The first technique involved generating additional parallel data from monolingual data via back-translation and the second technique involved training a multilingual model on a joint set of bilingual corpora. We found that both techniques resulted in higher BLEU scores compared to the baseline models. We also found that the model trained on augmented parallel data outperformed the multilingual model for both language pairs. For the multilingual model, we saw a greater improvement for the translation from English to IsiZulu and found that training models with target languages having similar semantics increase translation performance for the language pair with the smallest dataset size. In addition, we investigated how the size of the Byte Pair Encoding token size affects the translation performance of the models and the result showed that both languages performed better on smaller BPE token sizes. We attribute this low performance when using a larger BPE token size as a result of using a small size dataset.