About
Description
Association rules are generated for basket-like datasets where each instance in the dataset is a set of items. e.g. A market database containing a list of transactions where each transaction contains a list of items that are bought. Rules relate a set of items, itemset_left, with another set of items, itemset_right. This relation implies that if a transaction contains itemset_left it is likely that the items in itemset_right are in the same transaction.
A list of items is called an itemset. An itemset in a dataset may have a support level. An Itemset’s support level represents the percentage of transactions that the itemset appears in the dataset.
An association rule may have a confidence level associated with it. The confidence level of a rule represents the probability that if itemset_left appears in a transaction, itemset_right will also appear in that transaction.
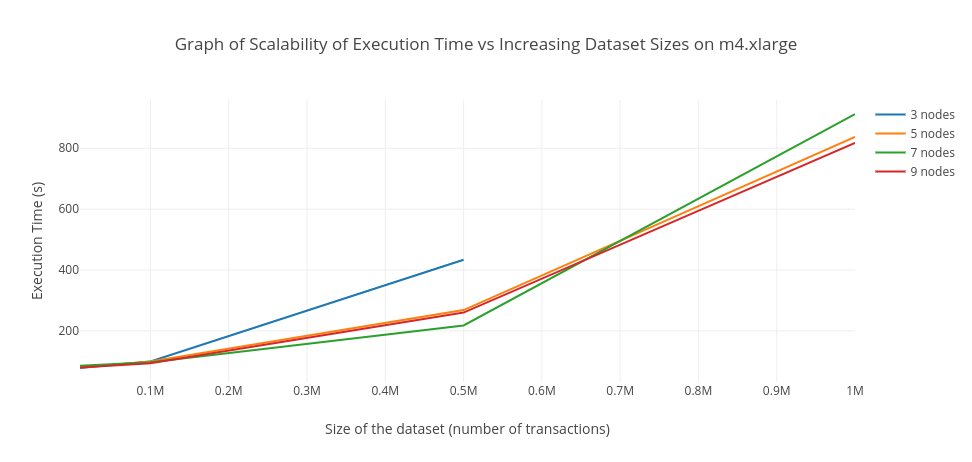
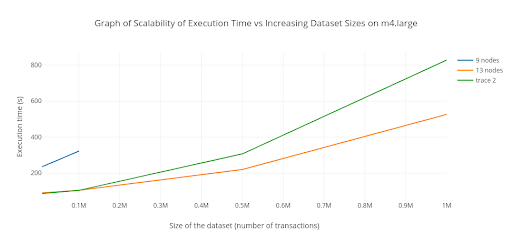
The Association Rule Mining module generates association rules in basket-like datasets that are provided to it via the front-end Web-based interface. In this context, The rule mining module generates rules for Twitter data provided. The rule mining module focuses on the implementation of a scalable data mining algorithm to provide short execution times for large datasets. The module runs in Hadoop cluster environments, specifically on Amazon Web Services’ EMR service. Various parameters can be specified to the module to determine the rules to generate, such as a minimum support level for itemsets to find rules for or a minimum confidence threshold to limit the amount of rules generated.
Design
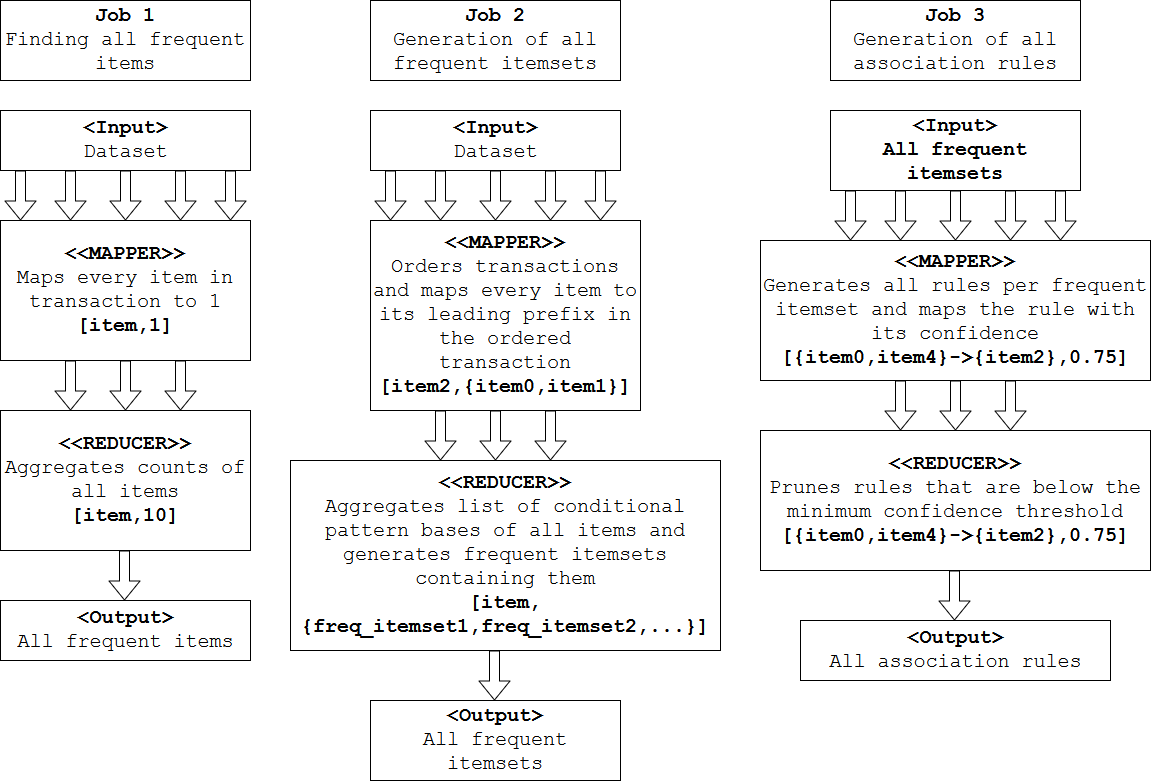
The rule mining module was developed as a Hadoop program to run on any Hadoop-based cluster, specifically for AWS’s EMR. To this extent, Java was used to develop the module. The module is an implementation of the Frequent-Pattern Growth algorithm for Association Rule mining (FP-Growth). FP-Growth is implemented as three Map-Reduce jobs:
Results
The module was evaluated by correctness and scalability. This was done by using data generated from IBM’s Synthetic Dataset Generator [2]. A validation test was also performed by running the module on Twitter data to validate that it could generate rules for the Twitter data.
Correctness: Generated results were compared to expected results generated from IBM’s Synthetic Dataset Generator. It was found that 95% of generated itemsets were found to match and rules generated were within a 15% deviation from expected values.
Scalability: The rule mining module performs on the order of minutes for datasizes up to 1 000 000 transactions and is found to perform better using more nodes. However, the algorithm is seen to slow down again if it is run on a configuration with too many nodes.