Neural Question Generation
Overview and Background
The paper by Ros et al. (Generation of Student Questions for Inquiry-based Learning) is the only study done thus far that investigates generating student questions from lecture transcripts. They investigated this by fine-tuning the language model t5-base and a pre-trained t5-base model, docT5query (pre-trained on MS MARCO passage, large IR dataset) on a small dataset of lecture transcripts and student-asked questions. They also used prefix-tuning.
This study focuses on constructing and using various datasets to train both t5-base and docT5Query on. To serve as a baseline, two of Ros et al.'s models, t5-base-prefix and docT5query-prefix, were replicated. Three datasets are constructed and t5-base and docT5query were trained on them, the three datasets are; IR-small, a small diverse dataset composed of 17 information retrieval datasets, LearningQ, a large education dataset that contain education content from online course and questions asked by students, and lastly, reading-comp, which is composed of five reading comprehension datasets (also known as question-answering dataset, without the answers in this case). IR-small was used to determine if similar results to the replicated docT5query-prefix model could be achieved on a smaller dataset, while LearningQ and Reading-comp were used to investigate whether the overall quality of the questions could be improved by training t5-base and docT5query on better quality questions.
Methods
Creating a baseline (Replication):
To establish a baseline, two of Ros et al.'s models were replicated, t5-base-prefix and docT5Query-prefix, using the same parameters and library versions. However, due to not having access to the same GPU that they used to fine-tune their models, the automatic metrics and generated questions from the replicated models differ slightly to those reported in the Ros paper.
The datasets created and used:
IR-small
IR-small is diverse collection of 17 small Information retrieval datasets, it contains user queries and supporting documents, 17k samples, and covers a wide range of topics, maths, stats, politics, economics, science, English, writing. The documents used were those that had a high relevance score. The only model IR-small was used on is t5-base as docT5query was previously trained on a larger IR dataset.
LearningQ
LearningQ is a large dataset of student questions and long passages of text from learning platforms, and contains 227k samples. This dataset closely resembles the small lecture-transcript and questions dataset in that the questions contained within this dataset were created by students and instructors from online learning material. Both t5-base and docT5query were trained on this dataset.
Reading-comp
Reading-comp is a large dataset containing five reading comprehension datasets (sometimes known as question answering datasets), and contains 354k samples. Except for one dataset, NarrativeQA the other four are shallow datasets (i.e. the answers are directly in the text), however, in this research we simply use the questions and contexts from each dataset. Both t5-base and docT5query models that were trained LearningQ were further training on this dataset.
Lecture-transcripts and Questions
The Lecture-transcripts and questions dataset, is from two MOOCs (Massive Open Online Courses) covering topics in information retrieval, “Retrieval and Search Engines” and “Text Mining and Analytics”. There are 90 lectures across the two MOOC’s, each lecture contains a complete transcript and questions asked by students, the transcripts are timestamped to indicate where in the lecture a question was asked. There are 536 lecture-question pairs.
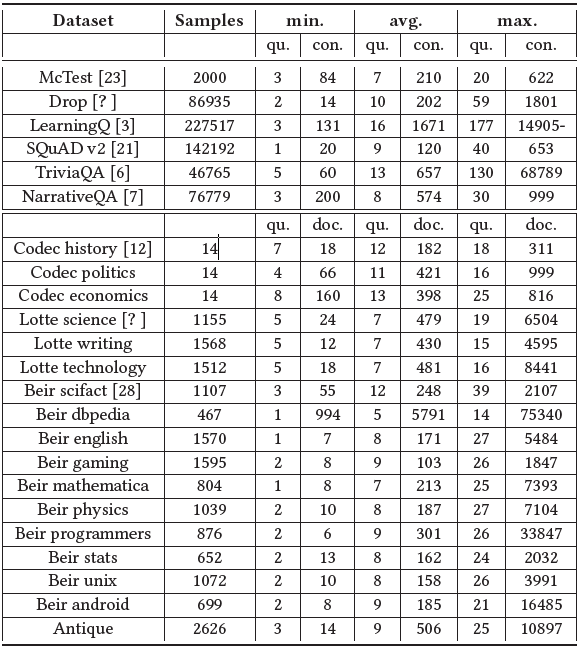
The first half of the table is an overview of the Question- Context (LearningQ and Reading-Comprehension datasets) dataset statistics: Minimum (The number of words in the shortest question and context), Average number of words and Maximum (The number words in the longest question and context). The 2nd half of the table is an overview of the Query-Document (IR-small) dataset stats. qu. = question or query, con. = context, doc. = document.
Training (on IR-small, LearningQ, and Reading-comp):
Fine-tuning:
Results
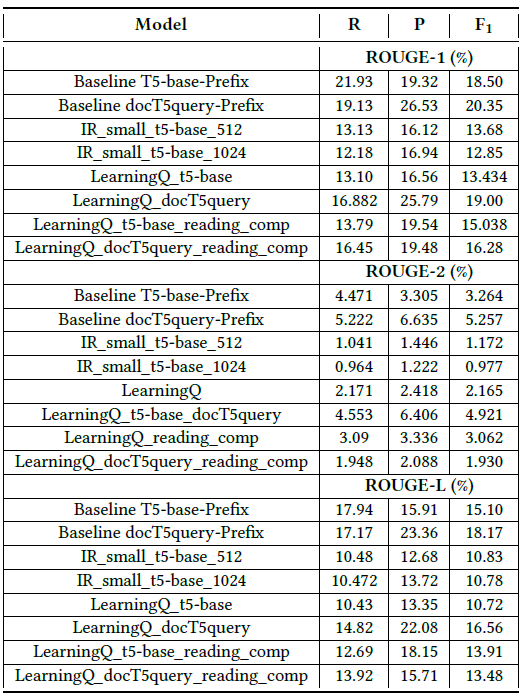
Table of the recall, precision, and F1 scores for ROUGE-1, ROUGE-2, and ROUGE-L measurements on the test set of the Lecture Transcripts and Questions dataset. All models used prefix tuning. R = Recall, P = Precision.

Grammatical Correctness in Blue, Logical Sense in Orange and Relevance in Grey


Graph of the average scores of the three categories (for the two template-based systems and the three neural models) across all 10 contexts evaluated by our participants. Grammatical Correctness in Blue, Logical Sense in Orange and Relevance in Grey
Results summary:
Conclusions and Future Work
Finetuning t5-base on a diverse small IR dataset (17k samples) does not yield similar results to the replicated docT5Query-prefix model which is trained on a large (500k samples), the most likely cause is due to the underlying language model (t5-base) having a much greater influence on generated questions by the IR-small model. The internal quality assurance and external human evaluation illustrated that the models trained on LearningQ and Reading-comp generate better quality questions when they have been trained on docT5query, thereby exposing the model to both query-document and question-context pairs. Training doct5query on LearningQ produced our best-performing model and it outperforms both baseline models. Exposing the model to many user generated queries and well-formed student questions appears to improve the overall quality of the generated questions, however, there is no clear benefit to further training the models on shallow Reading-comp datasets.
The focus for future work should be on creating a collection of clean transcripts with corresponding student questions to improve the grammatical correctness of the questions. The grammar could also be improved with the addition of linguistic features and word embeddings to the input contexts and target questions.