Abstract
South Africa is a linguistically diverse country with 11 official languages. Nine of the languages are termed low-resource languages due to there being not enough electronic documents available for them. The exceptions are English and Afrikaans. Natural language processing techniques require electronic documents to extract content for processing to enable computers to understand, interpret and generate spoken languages. The goal of this paper is to assess the feasibility of using crowdsourcing to construct a gold- standard ASR corpus for isiXhosa. It involved collecting audio data, transcribing it with isiXhosa speakers, and applying several statistical methods to evaluate the transcriptions' quality and consistency. The corpus, while not without limitations due to small sample sizes and potential variations, represents a significant step towards addressing the scarcity of electronic linguistic resources in low-resource African languages.
Methods
This section outlines the methodology for creating a gold-standard ASR corpus for low-resource languages, specifically isiXhosa. The process includes participant recruitment, audio data collection, audio transcription, and statistical analysis tools.
Participant Recruitment
The study recruited isiXhosa-speaking students from the University of Cape Town, ensuring ethical clearance. Diverse participants were reached through emails and posters. They had to be fluent in isiXhosa and were compensated for tasks.
Audio Data Collection
Two sets of audio segments were gathered: structured audio from South African Broadcasting Cooperation news segments and unstructured audio from recruited participants. The unstructured audio included casual conversations with noise factors. The structured audio included formal speach without any noise factors.
Audio Transcription
The audio segments were transcribed using the Turkle web application hosted on Amazon Web Service. A pilot test ensured the application's functionality and usability.
Statistical Analysis
Data preprocessing involved removing translations, splitting text into words, converting to lowercase, and excluding English words. The following statistical techniques were conducted on the results:
- Inter-Transcriber Similarity: The Levenshtein distance was used to measure agreement between transcriptions.
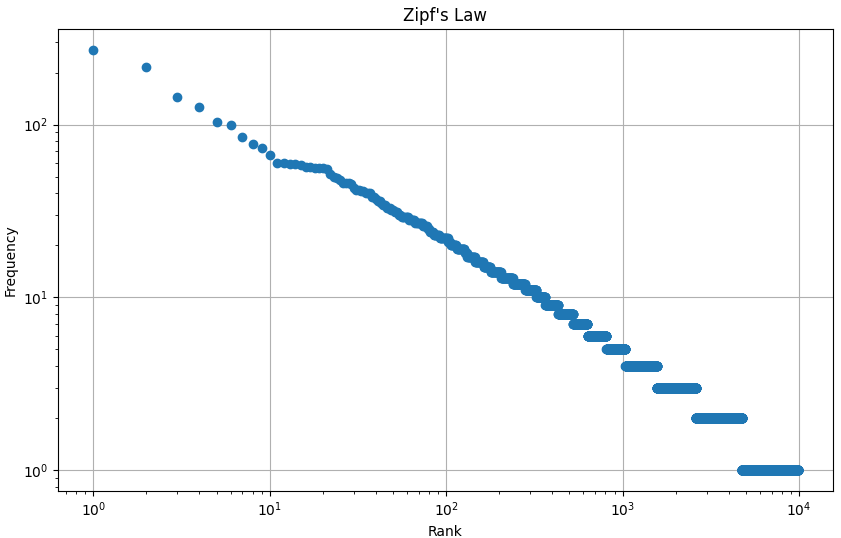
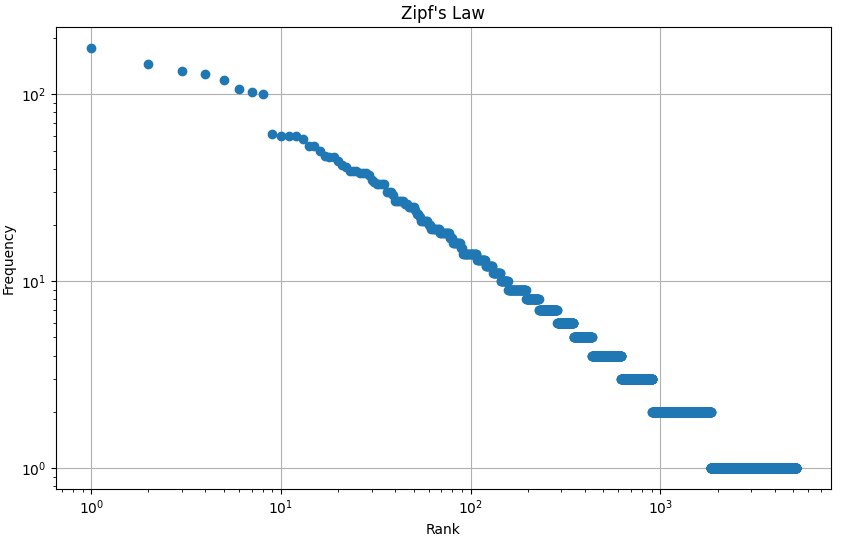
- Zipf's Law: Zipf's Law was applied to evaluate word frequency distributions in the corpus.
- Token-Type Ratio: The Token-Type Ratio (TTR) was used to assess the lexical richness and diversity of the corpus.
Results
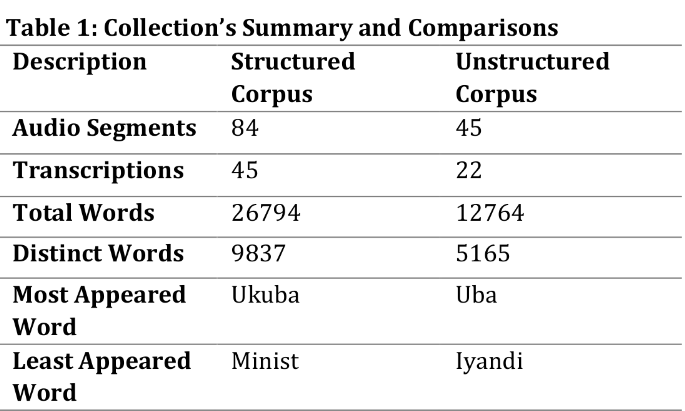
Two sub-corpora were developed for two audio sets—structured and unstructured. Statistical analysis on both corpora revealed:
- An above-average inter-transcriber similarity score of approximately 60%.
- A token-to-type ratio of approximately 2.5.
- Adherence to Zipf's law as seen in natural languages.
Conclusions
This study used crowdsourcing to create a gold-standard ASR corpus for isiXhosa, a low-resource African language in South Africa. The corpus had 26,794 structured and 12,764 unstructured audio segments. The findings highlighted the corpus's strengths and limitations, including varying transcription agreement, adherence to Zipf's Law, and a balanced vocabulary diversity. Despite some challenges, this research demonstrates the potential of crowdsourcing for building linguistic resources in low-resource African languages. It contributes to linguistic research, offering insights into language patterns and richness in isiXhosa, and provides a foundation for future collaborations to address linguistic resource shortages in African languages.
 © 2023 Research by Sabiha Shaikh
© 2023 Research by Sabiha Shaikh
