Abstract
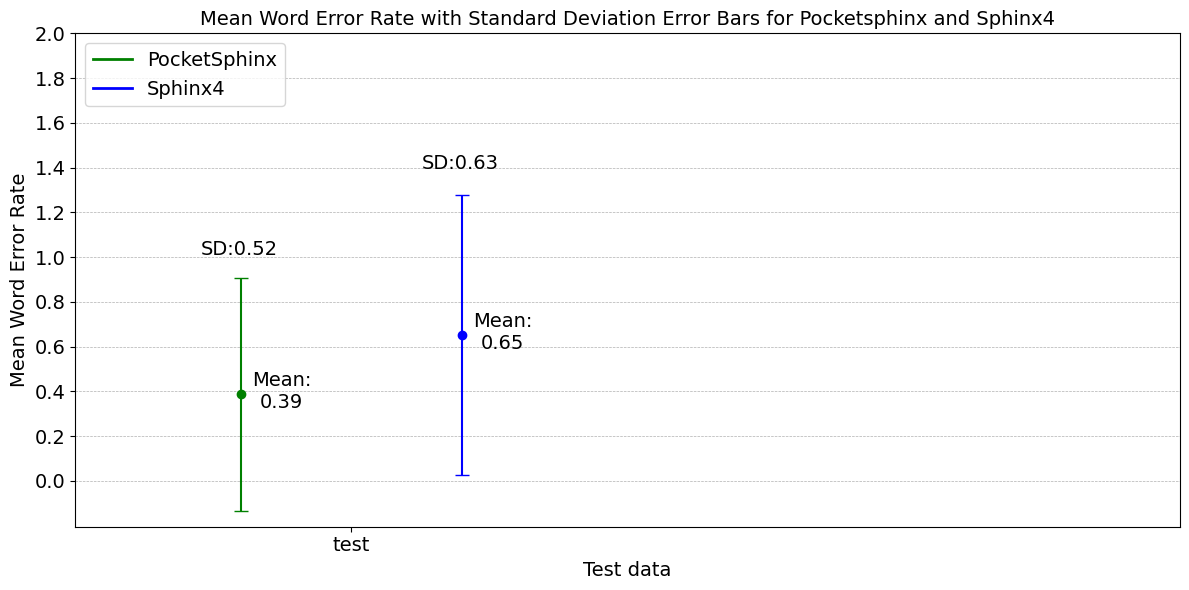
The lack of electronic linguistic resources in the southern Nguni languages, such as isiXhosa, negatively impacts computational and statistical systems that rely on these resources. Transcribing these languages would facilitate text-based research experiments and support multiple areas of natural language processing (NLP). This paper describes the methods used to create an isiXhosa automatic speech recognition (ASR) transcription system using the CMUSphinx speech recognition toolkit for South African Broadcasting Corporation (SABC) news. The accuracy of this system is evaluated by using metrics such as word error rate (WER), and the Levenshtein distance at the character and word level. Multiple experiments were conducted using a gold standard test corpus of approximately 40 minutes of SABC news and 3 hours of test audio provided by the South African Centre for Digital Language Resources (SADiLaR) website. The experiments done on the SABC news audio showed that the Levenshtein distances for the news anchor in the field were more accurate than the main news anchor and the distances for male speakers were more accurate than for females. Although Pocketsphinx performed better than Sphinx4 overall, both systems performed poorly on the SABC news audio, each with a WER of 100%. In comparison, the SADiLaR test audio had a WER of 39% for Pocketsphinx and 65% for Sphinx4.
Methods
The process involves building a language model and an acoustic model, audio segmentation, and evaluating the accuracy of two different speech recognition tools: Pocketsphinx and Sphinx4.
1. Building a Language Model
Datasets were obtained from the South African Centre for Digital Language Resources (SADiLaR). Building the language model was the first step, accomplished using the CMU Language Model Toolkit (CMULMTK) and data preparation. Language model training involved generating vocabulary and 'idngram' files, as well as converting the language model into 'arpa' and binary formats for compatibility with Sphinxtrain and CMUSphinx (Pocketsphinx and Sphinx4).
2. Building an Acoustic Model
To train the model, a specific file system structure was required, containing all the necessary files: language model, and phonetic and filler dictionaries. Data preparation for the acoustic model included creating the necessary file structure and organising the necessary data within this structure. Data pre-processing involved converting the raw text-to-speech datasets into a format expected by Sphinxtrain. The phonetic dictionary was initially incomplete, so a grapheme-to-phoneme (G2P) model was trained to complete it. Training on sphinxtrain, ran for a few hours, achieving a Word Error Rate (WER) of 30.9% and a Sentence Error Rate (SER) of 34.9% when tested with data from the NCHLT corpus.
3. Audio Segmentation and File Processing:
Audio segmentation was carried out using Python scripts and libraries like numpy and soundfile. The segmentation was based on the energy level of the speech, aiming to split the audio at points of low energy. However, manual segmentation was still required in cases where clear pauses were not detected. This manual intervention involved dividing longer segments and joining shorter ones that split mid-word to ensure a smoother flow. Once segmentation was completed, the source transcription files from the SABC news corpus were cleaned by converting all text to lowercase and removing punctuation. The cleaned text was organized with each audio segment's speech on a new line, facilitating a line-by-line comparison with hypothesis transcriptions to calculate transcription accuracy metrics.
4. System Development and Implementation
The system development and implementation involved the use of two speech recognition libraries, Pocketsphinx and Sphinx4. These were used for developing audio transcription systems, with Pocketsphinx implemented in Python and Sphinx4 in Java. The systems aimed to transcribe segmented audio files accurately.
5. Evaluation Metrics
Word Error Rate (WER) and Levenshtein distance (LD) were used to evaluate the accuracy of the transcriptions.
Word Error Rate
The Word Error Rate (WER) measures the accuracy of a speech recognition system by calculating errors in word substitution, deletion, or insertion, divided by the total words in the correct sentence.
\[ \text{WER} = \frac{\text{substitutions} + \text{deletions} + \text{insertions}}{\text{total number of words}} \]
Levenshtein Distance
The Levenshtein distance measures the number of changes required to make one word sequence match another, and in the project, it was applied at both word and character levels.
\[ \text{LD} = \text{substitutions} + \text{deletions} + \text{insertions} \]
Experimental Setup
- Experiments involved transcribing and evaluating test data and SABC news data.
- Comparisons were made between Pocketsphinx and Sphinx4, male and female and speech types.
Results
The results indicate that Pocketsphinx outperforms Sphinx4 on familiar data, but both perform equally on unfamiliar data. This might be due to the lack of maintenance for Sphinx4 by CMUSphinx. Overall, CMUSphinx performed poorly in transcribing isiXhosa SABC broadcast news, possibly due to small training datasets, short audio segments, and differences in speaker speed between training and test data. Not handling out-of-vocabulary (OOV) words could also affect the system's performance. Male speech segments performed better than female segments, likely due to pitch differences. Interestingly, field news speech sections performed better than main news anchor sections, possibly due to slower and clearer speech. Improving isiXhosa SABC news transcription would require a substantial amount of related training data, and exploring other toolkits and deep neural networks may be beneficial.


Conclusions
Although the experimental results showed that Pocketsphinx’s WER for the NCHLT test data was 39% in comparison to Sphinx4 with 65%, both systems performed poorly on the SABC news, unseen data, with a WER of 100%. Furthermore, when comparing male and female speakers it was seen that both systems performed better on male speech than female. Moreover, the field news had the best results amongst the different types of speech, with a better result than the main news anchor sections. The standard deviation for all the results showed a large variability between the data indicating that the data was widely spread out and not clustered close to the mean. Overall, the results show that CMUSphinx (Pocketsphinx and Sphinx4) does not perform accurately for isiXhosa SABC news.
 © 2023 Research by Kristen Basson
© 2023 Research by Kristen Basson
