Abstract
The scarcity of electronic resources for many South African languages, such as isiXhosa, poses a barrier to text-based research and experimentation. To overcome this barrier, this project investigates the feasibility of using mobile devices to automatically transcribe unstructured audio to generate a high-quality textual corpus using the PocketSphinx speech recognition toolkit across various dimensions such as background noise and conversational difficulties. The results reveal notable limitations, including high Word Error Rates (WER) and difficulties in capturing casual speech. Hardware differences and the rate of speech also influence performance. The results show that with the current data utilized, PocketSphinx is not viable for generating high-quality isiXhosa textual corpora on mobile devices, highlighting an urgent need for specialized model improvements.
Methods
1. Evaluation Metrics
Word Error Rate
The Word Error Rate (WER) measures the accuracy of a speech recognition system by calculating errors in word substitution, deletion, or insertion, divided by the total words in the correct sentence. \[ \text{WER} = \frac{\text{substitutions} + \text{deletions} + \text{insertions}}{\text{total number of words}} \]
Levenshtein distance
The Levenshtein distance measures the number of changes required to make one word sequence match another, and in the project, it was applied at both word and character levels. \[ \text{LD} = \text{substitutions} + \text{deletions} + \text{insertions} \]
2. Training database preparation
There are no pre-existing language or acoustic models for isiXhosa. Therefore, a new language and acoustic model must be trained using CMU SphinxTrain's command-line tools. SphinxTrain is tailored to develop speech recognition systems for any language with sufficient acoustic data and is compatible with the CMUSphinx recognizer.
2.1 Building a language model
Using the CMUCLMTK toolkit from CMUSphinx, an isiXhosa language model was developed based on the 56-hour NCHLT isiXhosa Speech Corpus and supplemented with the Lwazi isiXhosa TTS corpora from SADiLaR. After assembling a complete reference text, a unique vocabulary file was made, leading to the final ARPA format language model.
2.2 Phonetic dictionary and G2P model training
The isiXhosa phonetic dictionary file was obtained from the NCHLT-inlang pronunciation dictionaries from SADiLaR, which are broad phonemic transcriptions for 15,000 common words in 11 different languages. The phonetic dictionary contains the phonetic representation of all the words contained in the transcription files, allowing the decoder to understand how to pronounce each word.
The NCHLT-inlang isiXhosa dictionary was incomplete, lacking some words from the transcription file. To address this, Sequitur G2P was employed to train a grapheme-to-phoneme model, which generated phonetic representations for missing words using existing dictionary entries. After three training iterations, the final model filled in the dictionary gaps.
2.3 Training database structure
In the process of training an acoustic model, a training database is required. The database provides the data needed to create an acoustic model that extracts statistics from speech. The database was divided into two sections: a training section and a testing section. The testing section was about 1/10th of the total data size and did not exceed more than 4 hours of audio. The database prompts with post-processing contained the following database structure:
-
├─ etc
- ├─ your_db.dic (Phonetic dictionary)
- ├─ your_db.phone (Phoneset file)
- ├─ your_db.lm.DMP (Language model)
- ├─ your_db.filler (List of fillers)
- ├─ your_db_train.fileids (List of files for training)
- ├─ your_db_train.transcription (Transcription for training)
- ├─ your_db_test.fileids (List of files for testing)
- └─ your_db_test.transcription (Transcription for testing)
-
└─ wav
-
├─ speaker_1
- └─ file_1.wav (Recording of speech utterance)
-
└─ speaker_2
- └─ file_2.wav
-
├─ speaker_1
3. Acoustic model training
Acoustic model training occurred in two phases. Initially, it solely used the NCHLT isiXhosa Speech Corpus, resulting in a limited word recognition. The second phase integrated data from Lwazi isiXhosa TTS corpora, improving the model. During training, alignment errors between audio and transcription arose, requiring forced alignment and prompt filtering. The initial model had a WER of 30.1% and an SER of 33.2% as depicted in the table below. The second phase marginally improved the WER, but the SER remained consistent.
4. Android app integration and implementation
The app, adapted for isiXhosa speech recognition, initializes its recognizer upon launch. It continuously listens for the activation keyword "ubuntu". Once this keyword is detected, the app transitions into continuous recognition mode, capturing and processing audio input. After the audio input concludes, the app displays the transcribed version of the audio on the screen. A demonstration of how the Android app works can be found below.
5. Experimental Design
Data preprocessing
- Audio segmented into shorter chunks using pydub.
- Artificial city-traffic background noise added at varying levels.
- Casual isiXhosa conversations cleaned and normalized.
Different hardware
- Transcriptions tested on Android emulator and various phones (Samsung Galaxy A72, Samsung Galaxy Pocket, Xiaomi Redmi 6A).
Transcription procedure
- Audio played to the app for transcription.
- Each audio transcribed three times for accuracy, results averaged.
Results
1. Background noise
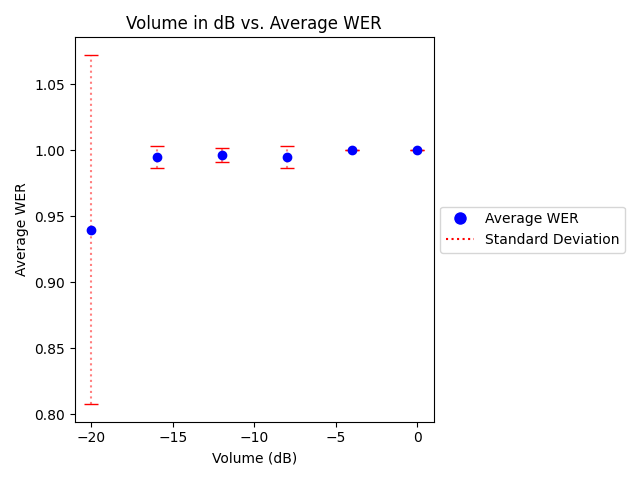
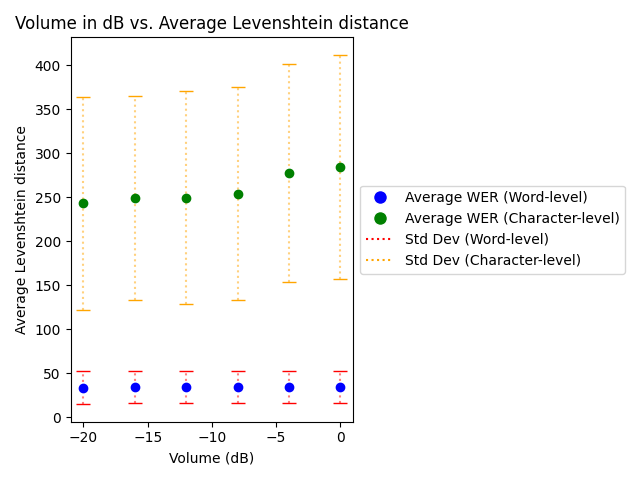
Background noise significantly affects transcription accuracy in the isiXhosa speech recognition system. High background noise (0 dB) resulted in a consistently poor Word Error Rate (WER) of 1, while a quieter -20 dB improved the WER to 0.94. The system's accuracy, as depicted by both the WER and Levenshtein distance metrics, considerably improves with decreased noise levels. Ambient noise obscures phonemes, making correct identification challenging; reducing noise allows more accurate phoneme recognition and, hence, better transcription. The results obtained are illustrated in the graphs below.
2. Casual conversations
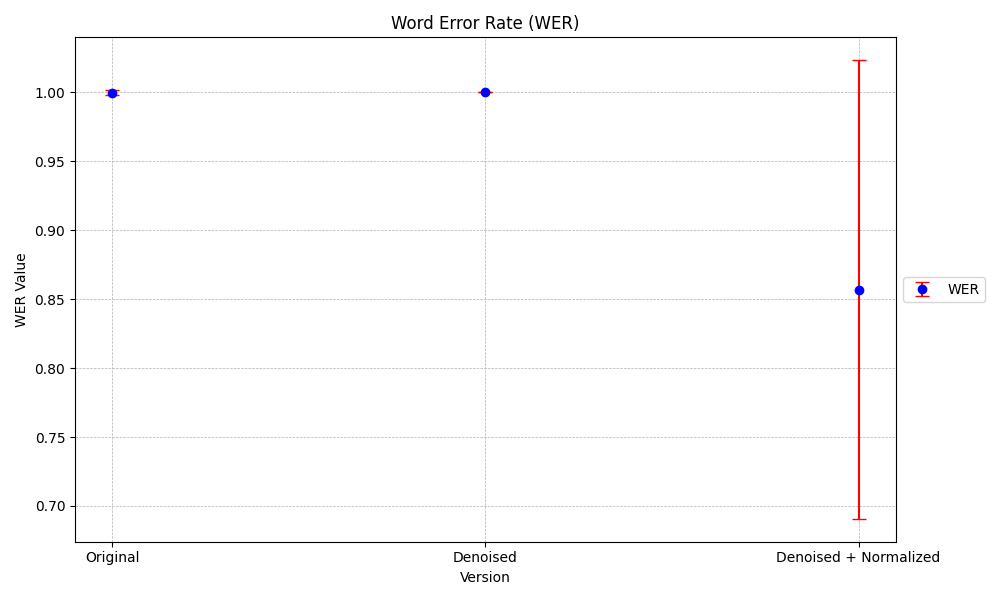
The isiXhosa speech recognition system struggled with conversational audio characteristics like overlaps and interruptions, yielding a high Word Error Rate (WER) of 1, even after removing background noise. However, normalization improved the accuracy, decreasing the WER to 0.86. The system faced difficulties with code-switching between English and isiXhosa, often missing or misinterpreting words, especially when English was introduced. Additionally, slang, acronyms, and colloquialisms presented challenges due to the system's training primarily on formal isiXhosa datasets. The results obtained are illustrated in the graphs below.

3. Hardware implications on transcription accuracy
Three mobile phones were tested for transcription accuracy. The Xiaomi Redmi 6A was the best performer with a WER of 0.36 as seen in the table below, while the Samsung Galaxy Pocket had the poorest results with a WER of 0.77. The Samsung Galaxy A72 had intermediate performance with a WER of 0.49. Differences in performance may stem from variations in microphone quality and onboard audio processing technology, emphasizing the importance of considering hardware characteristics in speech recognition on mobile devices.
4. Implications of gender on transcription accuracy
The speech recognition system's performance was assessed for both male and female speakers. Female voices had a slightly better WER of 0.98 compared to males at 0.99 as depicted in the table below. Females also had marginally better results in Levenshtein word and character distances. However, male voices showed more consistency in WER but greater variability in Levenshtein distances compared to females.
5. Rate of speech
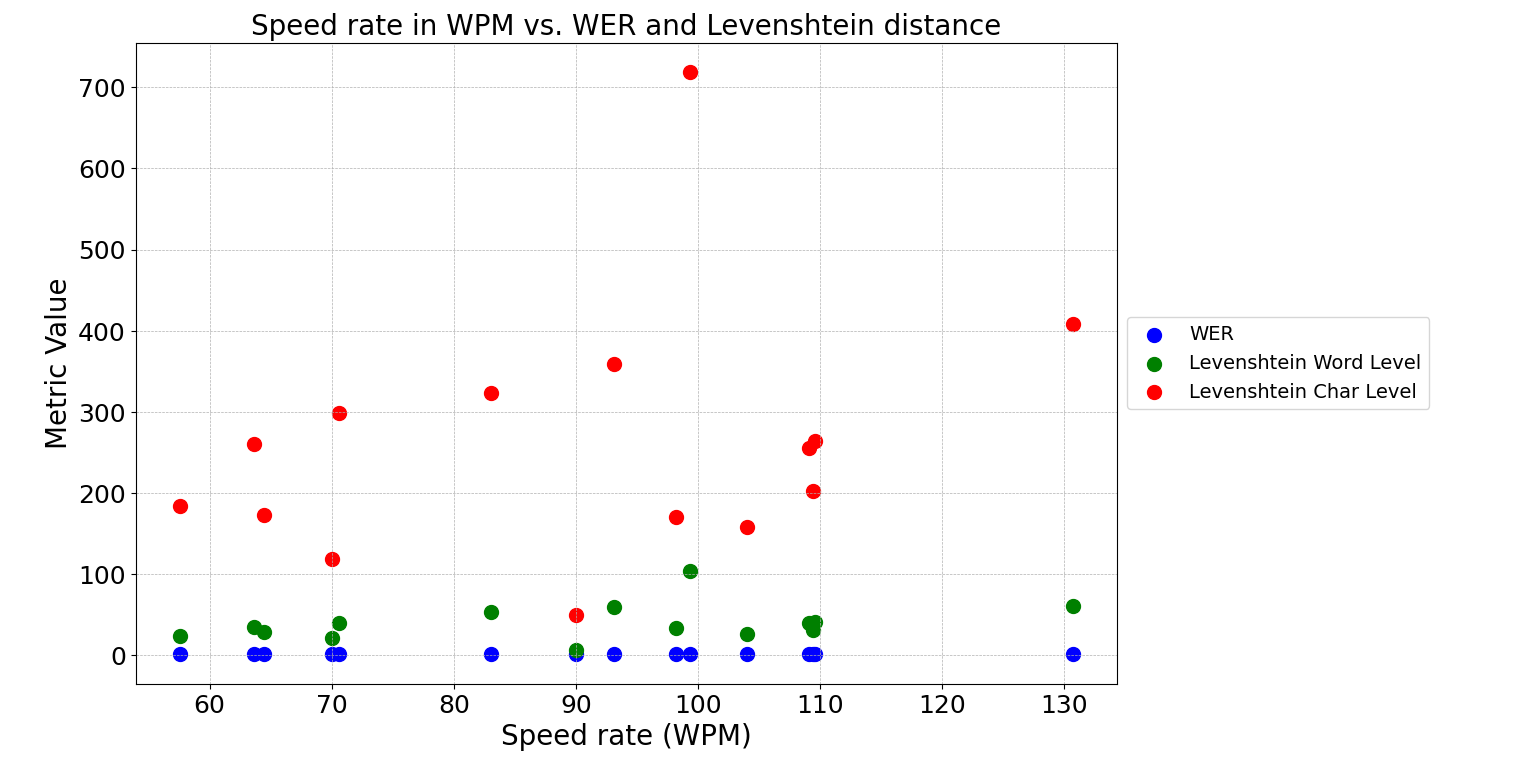
The isiXhosa speech recognition system's acoustic model was trained on slow speech rates, up to 70 WPM. Despite this, the system consistently produced high WERs between 0.95 and 1 for various audio samples, even those with rates below 70 WPM. Factors like missing words in the training vocabulary may affect the system's accuracy. The results obtained are illustrated in the graph below.
Conclusions
The evaluation of the PocketSphinx Android app for isiXhosa speech recognition revealed considerable flaws in the system's capacity to automatically transcribe unstructured audio on mobile devices. As the use of mobile phones surges in sub-Saharan Africa, the potential of mobile transcription to facilitate electronic resource creation for low-resource South African languages is evident. According to the results and data used, it is presently not possible to produce a high-quality textual corpus on a mobile device using the PocketSphinx speech recognition toolkit without making substantial improvements. Noise sensitivity and transcription of informal conversations are only a few of the difficulties that must be overcome to improve the accuracy of transcription. These problems underscore the urgent need for model improvement, flexible training, adaptable algorithms, and device-centric optimization. While promising in its current condition, there is still a long way to go before mobile devices can be effectively used for the gathering and creation of high-quality linguistic data.
 © 2023 Research by Fardoza Tohab
© 2023 Research by Fardoza Tohab
