Archive of Archives: User Interface
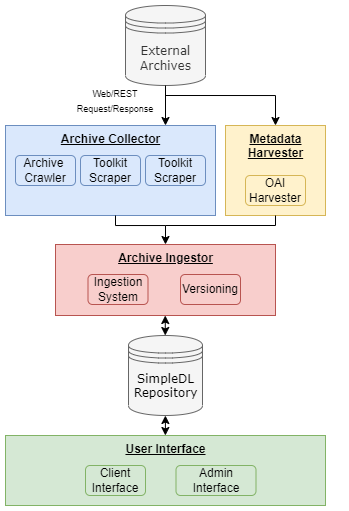
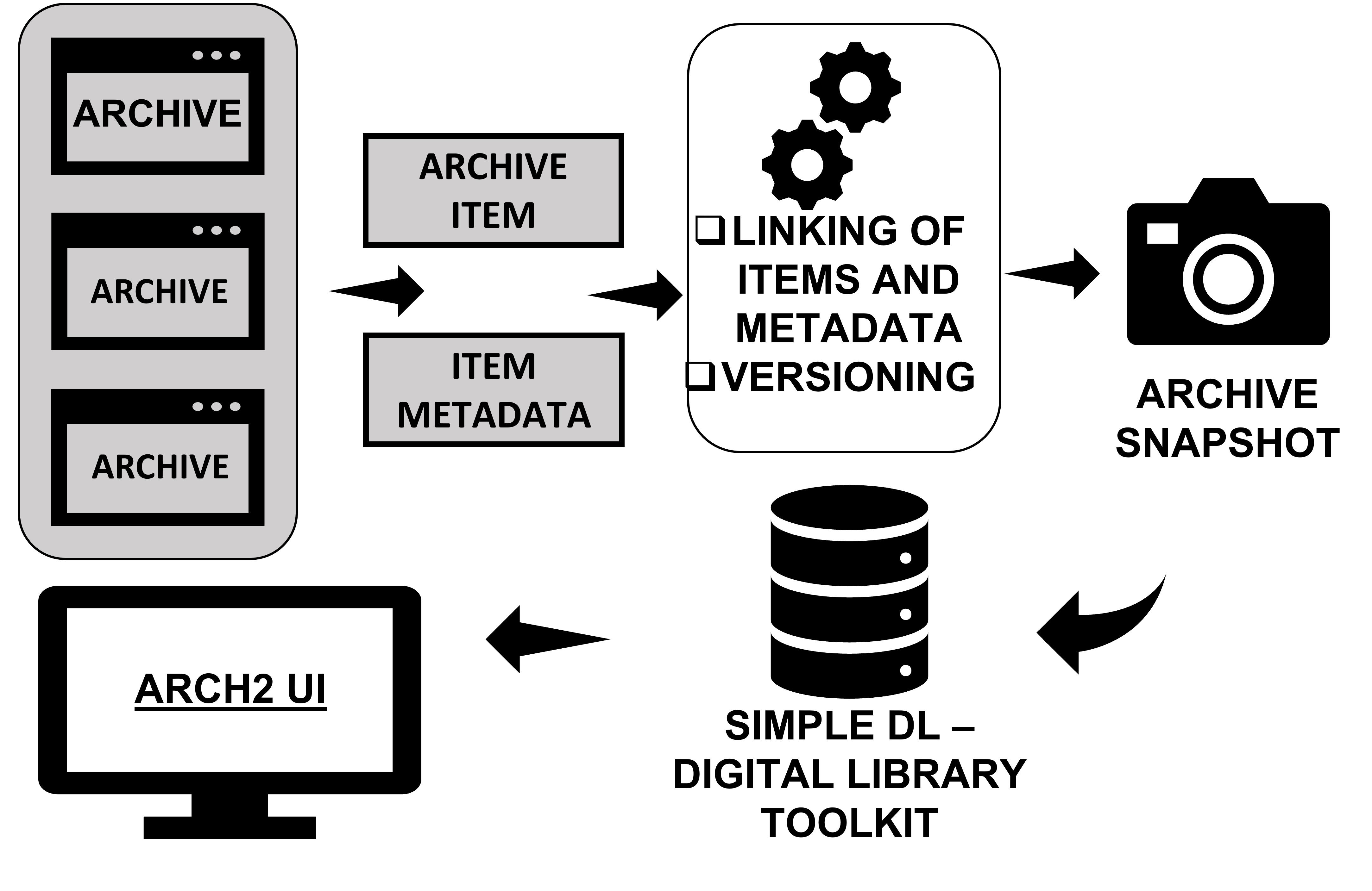
Creating an archive of archive user interface requires providing features that differentiate it from a standard archive. The current User Interface prototype implemented three points of differentiation. First, displaying what the stored digital archive originally looked like so that it is clear it is a full archive and not just a digital record. Second, to show the evolution of the archive over time, giving people insight into how archives change even when their individual records stay the same. Finally, providing a way for administrators to add and manage full archives rather than the standard archive records. All these features were evaluated on their usability through user interviews. Thematic analysis on the results showed that the presented features were all easy to use and easy to learn, which suggests that the proposed features will be suitable for future work into an archive of archives.
~ By Callum Fraser