Baseline LSTM
The Simple Child
An LSTM is a type of Recurrent Neural Network, which is formed by adding a short and long term memory unit to an RNN. The addition of memory units allows the network to deal with the correlation of time series in the short and long term, and store dependencies that it deems important from earlier epochs of training.
LSTMs have cells in the hidden layers of the neural network, which have three gates: input, an output, and a forget gate. These gates control the flow of information which is needed to predict the output in the network. The gates that are added to an LSTM cell allow LSTMs to learn long term dependencies, since they are able to retain information from multiple previous time-steps.
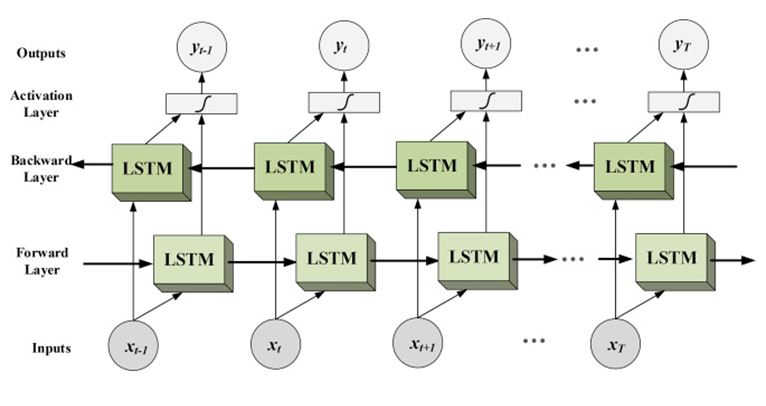
The image on the right is an example of an LSTM cell. Input is received from the previous cell and passes through the forget gates, where values deemed unimportant are dropped. Eventually new values are sent to the next cell through the output gate.

Bidirectional LSTM
Going Back and Forth
A Bidirectional LSTM runs input from both past to future, and future to past. This approach preserves information from the future and, using two hidden states combined, it is is able in any point in time to preserve information.
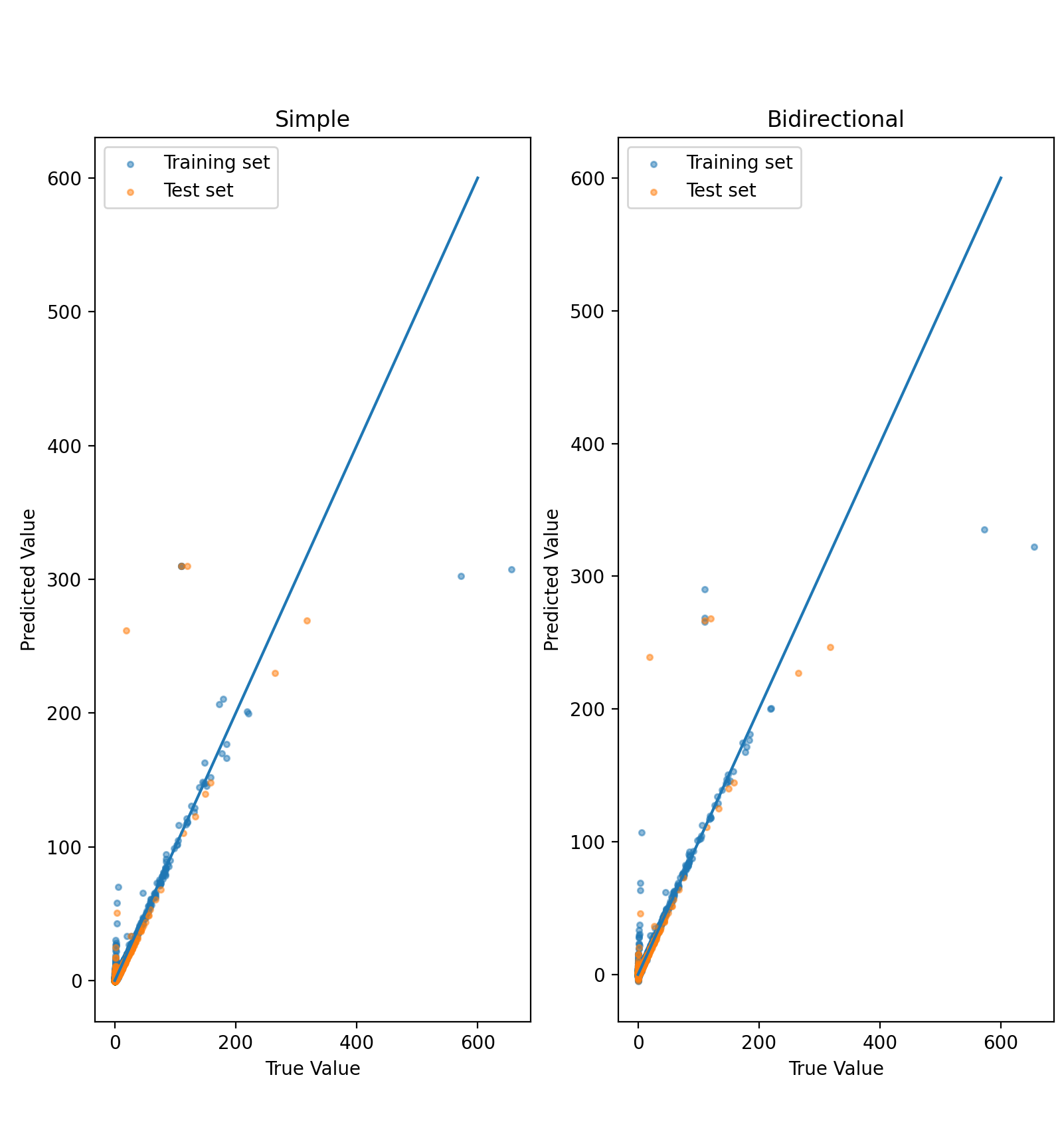
The Bidirectional LSTM fitted to the training data very well, and had the lowest validation loss of all the LSTM models. Since information is considered from both the past and the future, it may have considered future flows which the other models were not aware of yet. During the prediction phase, the Bidirectional LSTM had a higher error rate than the Simple and Stacked LSTM which led us to believe it was overcompensating for the fluctuations in traffic we saw later on.
The results show that there is no benefit to using the Bidirectional model for training and predicting network traffic on the SANREN, as its complexity does not yield an improvement in prediction accuracy compared to the Simple LSTM.
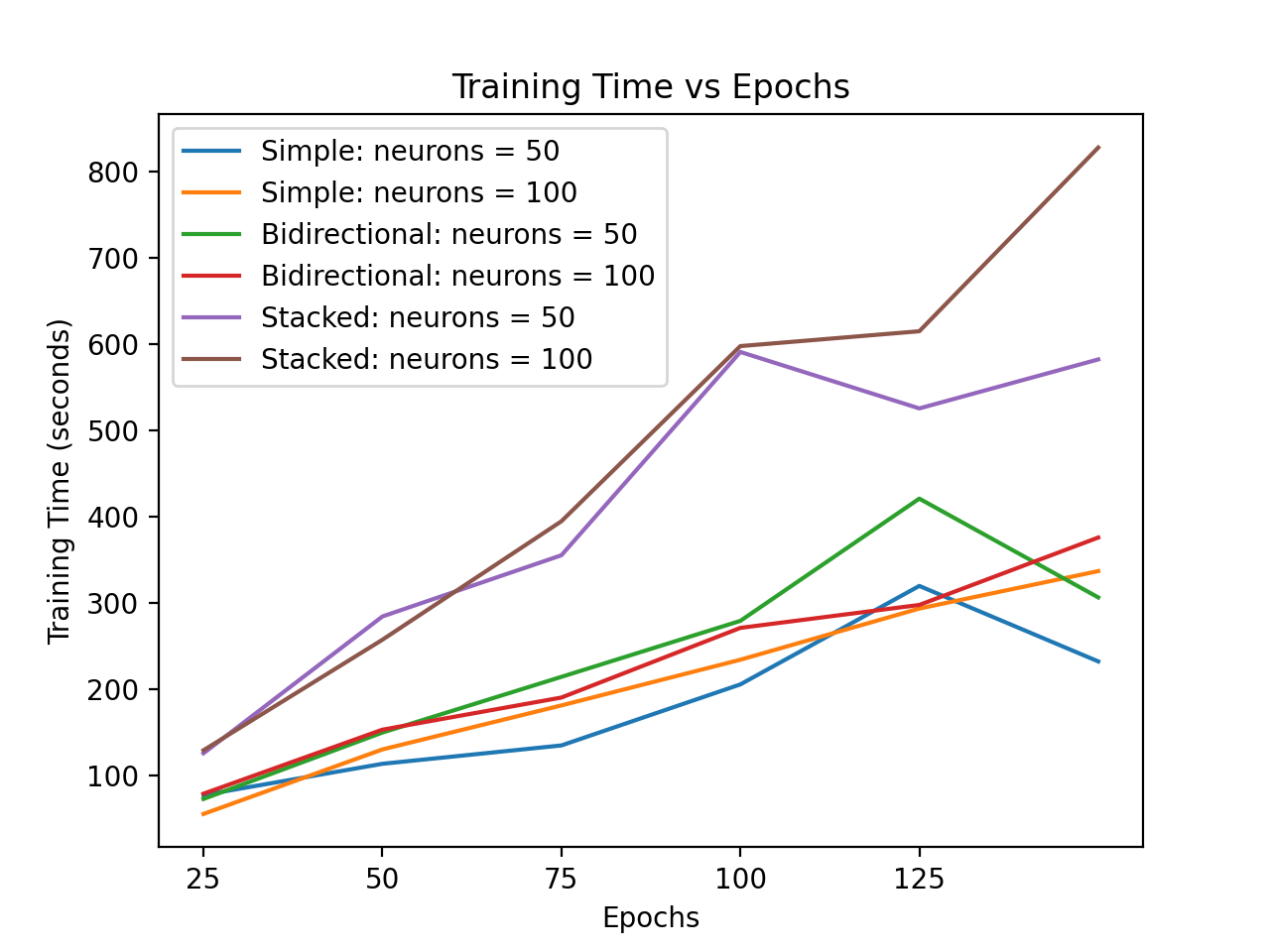
Hyperparameter Tuning
It's A Fine Line
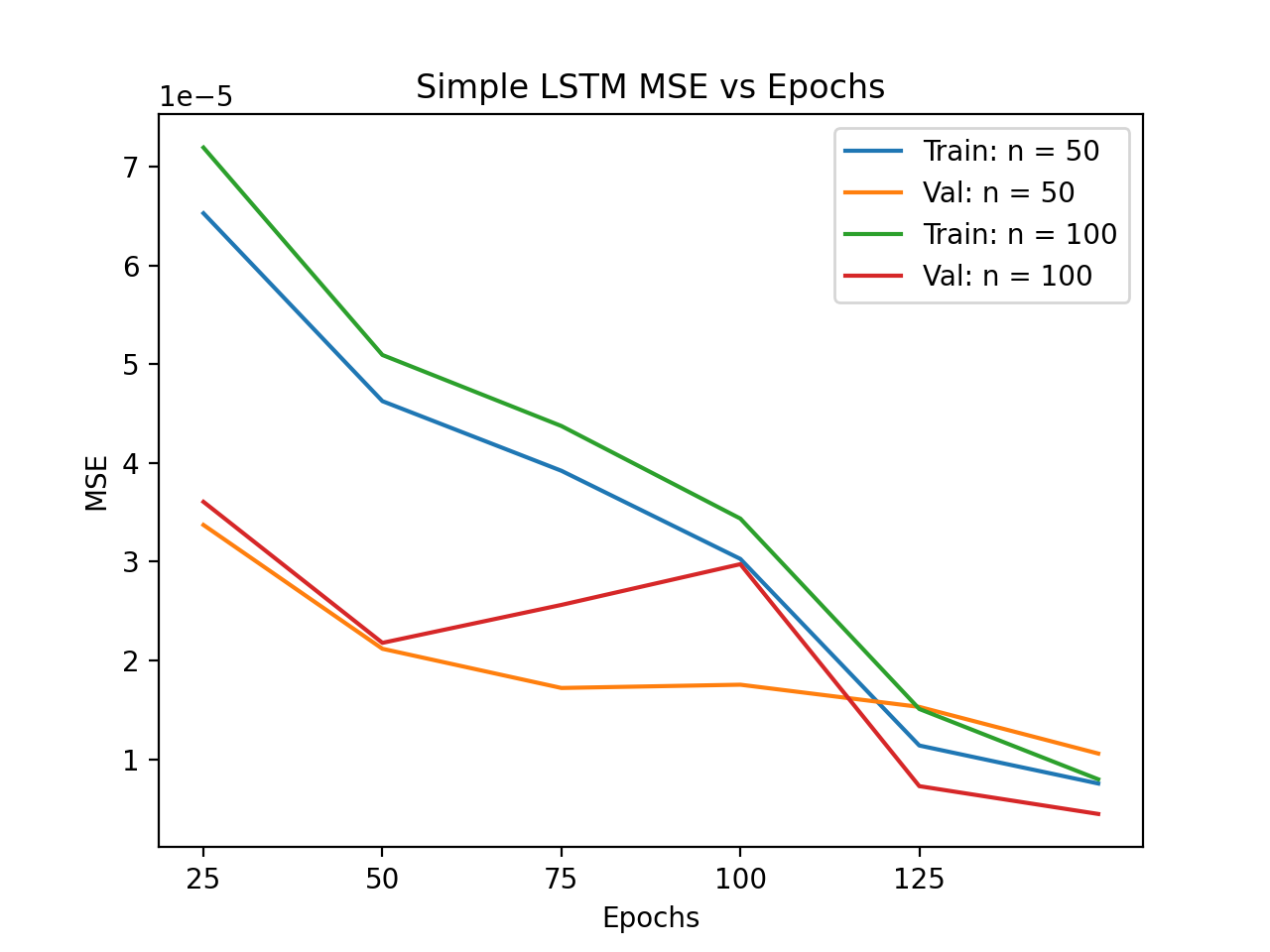
Training and validation loss allowed for the optimal hyperparamters to be chosen. When validation loss reached a minimum, training was stopped. Including more neurons, or the number of memory units in each layer proved to be advantageous. However, there is no such thing as a free lunch. Training time too increased, as more neurons were added. Both the Simple and Bidirectional LSTMs maintained a consistently lower training time than the Stacked LSTM. They are less complex than the Stacked LSTM, using less layers too.