Project Overview
Search engines provide a very useful tool for finding information that may be stored on the World Wide Web or any particular database. However, for African languages, it is a challenge to find information due to the lack of technologies and algorithms that support the retrieval of this information. IsiZulu is one of South Africa’s indigenous languages understood by over 16 million speakers. There is a large and increasing amount of IsiZulu documents on the Internet, however, there is no easy and effective means to get access to them. This creates a need for an IsiZulu information retrieval system. This project looks at the development of an IsiZulu search engine, which belongs to a group of African languages termed the Bantu languages. The system was built using existing technologies that were customized to suit the morphology of the language.
System Overview
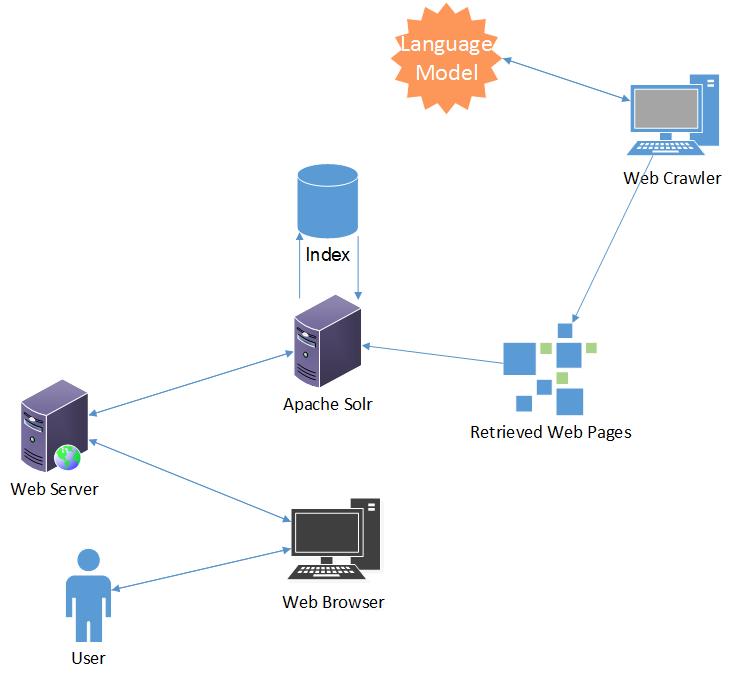
There are two main parts to the system which, are the indexing and retrieval of data, and the harvesting of web pages and documents from the World Wide Web. An outline of the technologies that were employed in the development of the system are as follows:
a) Web Server – a Web server is computer or software system that processes requests via HTTP(hypertext transfer protocol), which is a protocol used to distribute information through the World Wide Web (Webopedia, 2014). For this project, a web server is required to host the IsiZulu Search Engine web pages and publish the results of the requests that are sent through to the search engine.
b) Search Engine Interface – the search engine interface is the set of web pages that the user is going to interact with which will be hosted by the web server. Through this interface, a user is going to be able to submit a query that is based on a particular information need and be able to view the results from the search engine.The search engine interface will be accessbile via the web browser.
c) Apache Solr - Apache Solr is a search platform, which will primarily be used to index and retrieve documents based on a query supplied by the user. Additionally, the search platform will be customized through plugins and alteration of the schema properties to ensure efficient indexing and retrieval of documents.
d) Web Crawler - A web crawler is an Internet software application that systematically browses the World Wide Web to index the contents of websites or the Internet as a whole. Given a set of URLs as inputs, the crawler visits these URLs and based on its set of rules, indexes the page and scans for other URLs within the same page, which it can next visit. The crawler os used for harvesting IsiZulu text from the World Wide Web so that these pages can be indexed in the search engine.
e) Language model – a language model assigns a probability to a certain sequence of words to estimate the likehood of the sequence of being a particular language or a particular part of speech. Language modelling is used innatural language processing techniques that use a computational approach to a language. In this case, a language model will be used to classify a web page as either being written or having relations to the IsiZulu language.