Rule-Based Error Detector
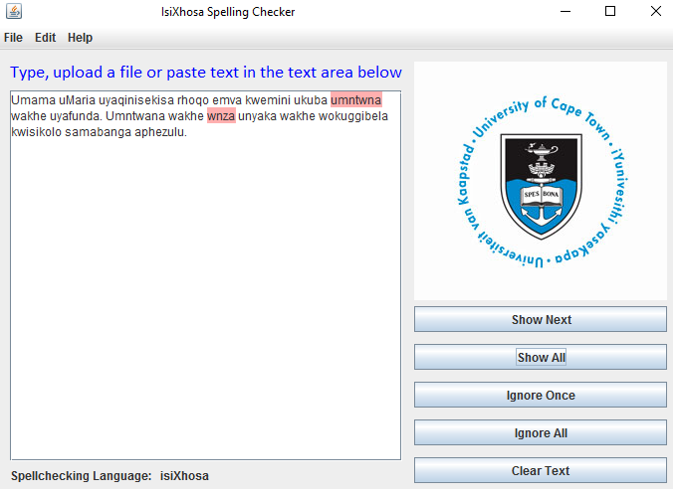
The Rule-based error detector for isiXhosa was implemented as a finite state transducer network, where we used the SFST-PL (a programming language for the tool SFST) which supports many different formats of regular expressions such as the ones used in grep, sed or Perl. Based on the morphology books that we were reading, we have developed rules for nouns, verbs, adjectives, pronouns and possessives. We have then used Java Swing for implementing the interface shown on the left.
Statistical based
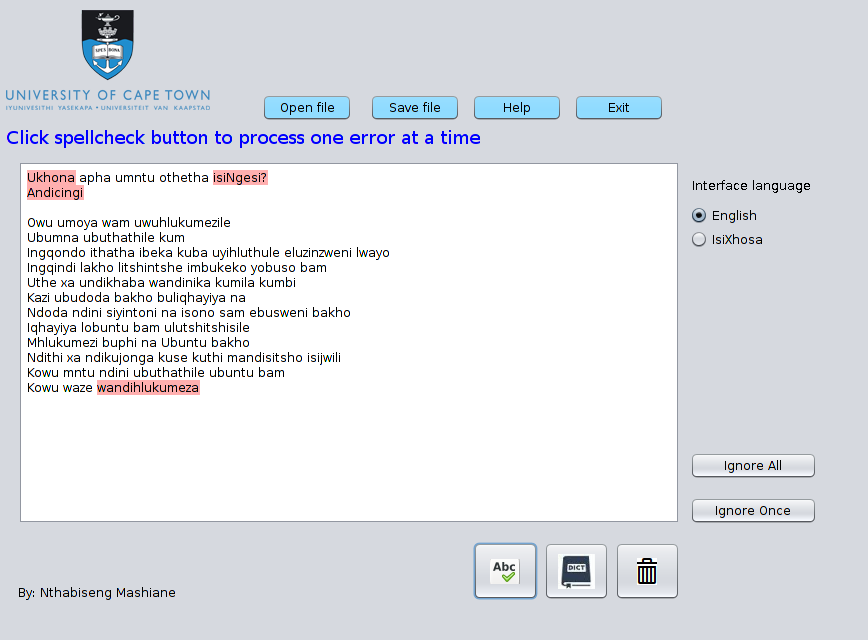
An error detection module was created using n-gram analysis.
Character trigrams were created then stored with their
corresponding frequency from the corpus. The probability of a trigram
existing in the corpus was calculated using the formula
P(w/N) = (wfrequency/N frequency)
where w is the word and N is the total number of words in
the corpus.
The trigram frequency is then compared with a predetermined
threshold (0.003) during error detection. If the frequency of the trigram is
below the threshold, the world is flagged as incorrect otherwise,
the word is flagged as correct.
IsiZulu Error Corrector
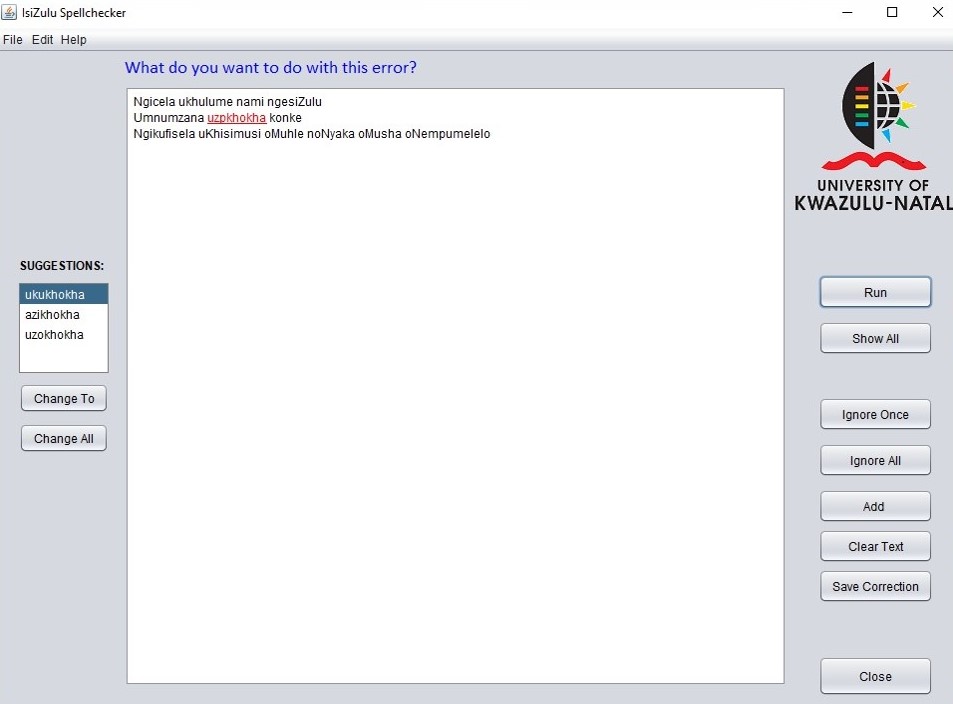
The isiZulu error corrector was developed using a statistical-based approach. Probabilities, Trigrams and the Levenshtein distance were used to obtain candidate corrections for words flagged as incorrectly spelled by the error detector. Java Swing was used to incorporate suggestions for flagged words into the existing isiZulu spellchecker interface, displayed on the left.
The Team
Siseko Neti |
Frida Mjaria |
Nthabiseng Mashiane |
Dr Maria Keet |
|||
Responsible for the implementation of the rule-based spelling error detector for isiXhosa. |
Responsible for the implementation of the spelling error corrector for isiZulu. |
Responsible for the implementation of the statistical-based spelling error detector for isiXhosa. |
Project supervisor |
|||

|

|

|

|
|||